Title :¶
LSTM v/s GRU
Description :¶
The goal of this exercise is to compare the performance between two popular gating methods, i.e LSTM and GRUs:
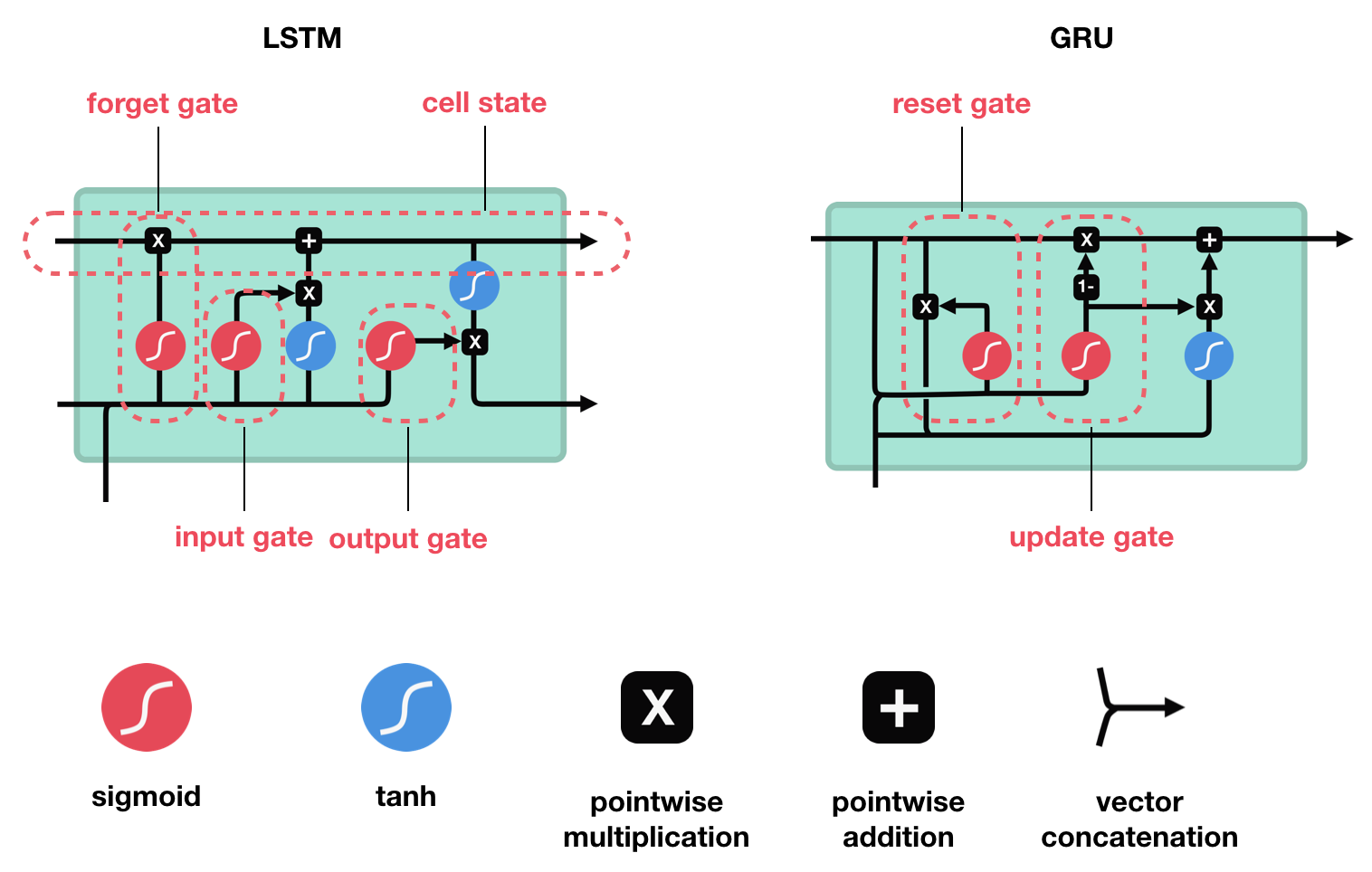
Instructions :¶
- Read the IMDB dataset from the helper code given.
- Take a quick look at your training inputs and labels.
- Pad the values to a fix number
max_wordsin-order to have sequences of the same size. - Build, compile and fit a GRU model
- Evaluate the model performance on the test set and report the test set accuracy.
- Again build, compile and fit a model but use the LSTM architecture instead.
- Evaluate the LSTM model's performance on the test set and report the test set accuracy.
- Compare the performance of all the two models.
Hints:¶
tf.keras.layers.Embedding() Turns positive integers (indexes) into dense vectors of fixed size.
tf.keras.layers.LSTM() Long Short-Term Memory layer - Hochreiter 1997.
tf.keras.layers.Dense() Just your regular densely-connected NN layer.
LSTM¶
We will use both GRU and LSTM to perform sentiment analysis in tensorflow.keras and compare their performance using the custom IMDB dataset.
# Import necessary libraries
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.layers import RNN
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Model,Sequential
from tensorflow.keras.layers import Input,Dense,LSTM,GRU,Embedding
from tensorflow.keras.preprocessing import sequence
from prettytable import PrettyTable
import pickle
# We use the same dataset as the previous exercise
with open('imdb_mini.pkl','rb') as f:
X_train, y_train, X_test, y_test = pickle.load(f)
# Similar to the previous exercise, we will pre-preprocess our review sequences
# We fix the vocabulary size to 5000 because our custom
# dataset was curated with that
vocabulary_size = 5000
# Max word length for each review will be 500
max_words = 200
# we set the embedding size to 32
embedding_size=32
# Pre-padding sequences to max_words lenth
X_train = sequence.pad_sequences(X_train, maxlen=max_words,padding='pre')
X_test = sequence.pad_sequences(X_test, maxlen=max_words,padding='pre')
# We create the mapping between words and sequences
word2id = imdb.get_word_index()
# We need to adjust the mapping by 3 because of tensorflow.keras preprocessing
# more here: https://stackoverflow.com/questions/42821330/restore-original-text-from-keras-s-imdb-dataset
word2id = {k:(v+3) for k,v in word2id.items()}
word2id["" ] = 0
word2id["" ] = 1
word2id["" ] = 2
word2id["" ] = 3
# Reversing the key,value pair will give the id2word
id2word = {i: word for word, i in word2id.items()}
### edTest(test_chow1) ###
# Submit an answer choice as a string below (eg. if you choose option A, put 'A')
answer1 = 'C'
# Comparing with GRU model
embedding_size=32
hidden_size = 100
gru_model=Sequential()
# Add Embedding, GRU and a Dense layer
# Add Embedding layer with vocabulary_size, embedding_size and input_length
# Add GRU with hidden_size
# Add Dense layer with 1 unit and sigmoid activation
gru_model.add(Embedding(vocabulary_size, embedding_size, input_length=max_words))
gru_model.add(GRU(hidden_size))
gru_model.add(Dense(1, activation='sigmoid'))
gru_model.compile(loss='binary_crossentropy',optimizer = 'Adam', metrics=['accuracy'])
gru_model.summary()
### edTest(test_chow2) ###
gru_cnt_params = gru_model.count_params()
batch_size = 256
num_epochs = 3
gru_model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs)
gru_score = gru_model.evaluate(X_test,y_test)
print(f'Model accuracy on the test set is {gru_score[1]:.2f}')
### edTest(test_chow3) ###
# Submit an answer choice as a string below (eg. if you choose option A, put 'A')
answer2 = 'A'
# Comparing with LSTM model
embedding_size=32
hidden_size = 100
lstm_model=Sequential()
# Add Embedding, LSTM and a Dense layer
# Add Embedding layer with vocabulary_size, embedding_size and input_length
# Add LSTM with hidden_size
# Add Dense layer with 1 unit and sigmoid activation
lstm_model.add(Embedding(vocabulary_size, embedding_size, input_length=max_words))
lstm_model.add(LSTM(100))
lstm_model.add(Dense(1, activation='sigmoid'))
lstm_model.compile(loss='binary_crossentropy',optimizer = 'Adam', metrics=['accuracy'])
lstm_model.summary()
### edTest(test_chow4) ###
lstm_cnt_params = lstm_model.count_params()
batch_size = 256
num_epochs = 3
lstm_model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs)
lstm_score = lstm_model.evaluate(X_test,y_test)
print(f'Model accuracy on the test set is {lstm_score[1]:.2f}')
# Finally, we compare the results from the three implementations above
pt = PrettyTable()
pt.field_names = ["Strategy","Test set accuracy"]
pt.add_row(["GRU RNN",f'{gru_score[1]*100:.2f}%'])
pt.add_row(["LSTM RNN",f'{lstm_score[1]*100:.2f}%'])
print(pt)
🍲 Which variant is better, LSTM or GRU?¶
Both LSTM & GRUs solve the vanishing gradient problem of RNNs but each has their advantages and disadvantages. (Read this paper for a thorough analysis of the two methods) Based on your understanding, which architecture is more appropriate for the current analysis?
### edTest(test_chow5) ###
# Type your answer within in the quotes given
answer3 = 'LSTM'