Key Word(s): ??
Title :¶
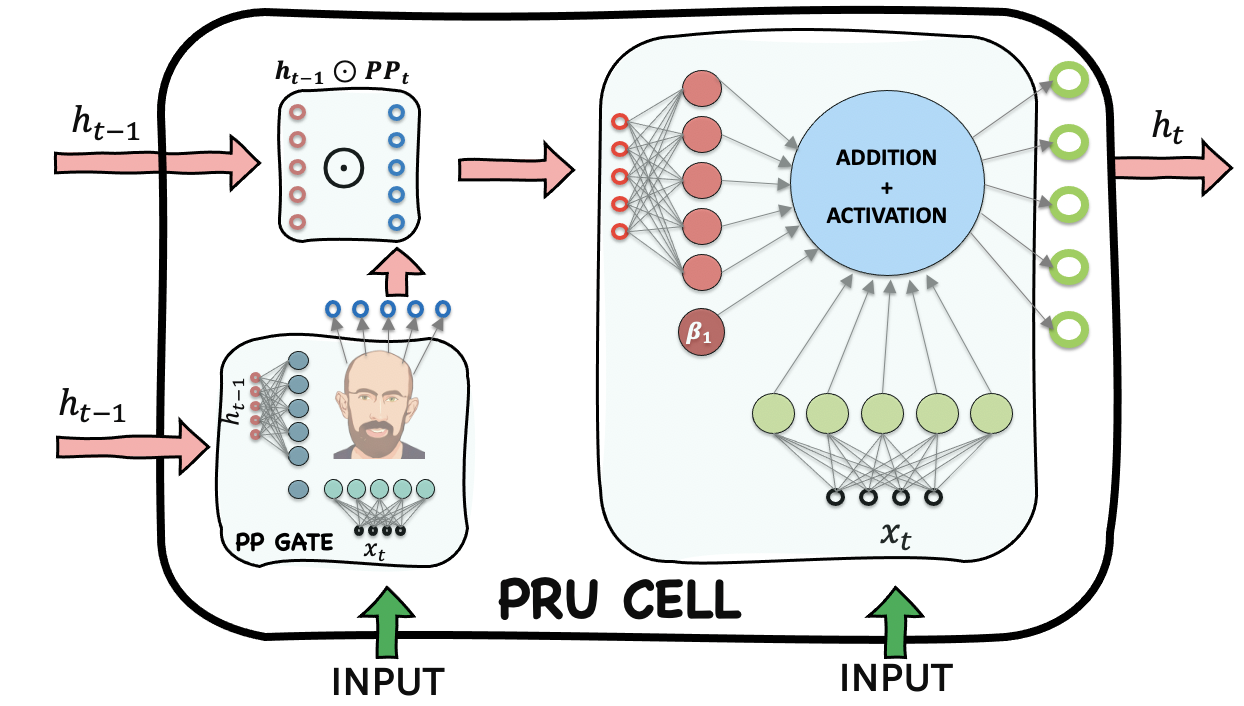
Pavlos Recurrent Unit
Description :¶
The goal of this exercise is to build the Pavlos Recurrent Unit discussed in class.
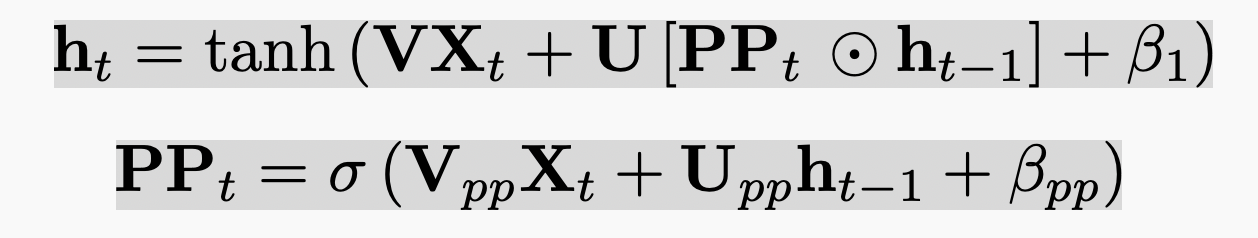
Alternative notation used in the exercise:

Instructions:¶
- Read the IMDB dataset from the helper code given.
- Take a quick look at your training inputs and labels.
- Pad the values to a fix number
max_wordsin-order to have sequences of the same size. - Fill in the helper code given to build the PRU cell.
- Using the tensorflow.keras Functional API, build, compile and fit the PRU RNN and evaluate it on the test set.
- For reference, also refit the model with a vanilla RNN and a GRU.
- Again evaluate the model performance on the test set of both models and compare it with the PRU unit.
Pavlos Recurrent Unit 
In this exercise, we will build the PRU as discussed in class to perform sentiment analysis in tensorflow.keras. We will continue to use the custom dataset from the previous exercise.
In [1]:
# Import necessary libraries
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.layers import RNN
from tensorflow.keras.models import Model,Sequential
from tensorflow.keras.layers import Input,Dense,Embedding
from tensorflow.keras.layers import SimpleRNN
from tensorflow.keras.preprocessing import sequence
import pickle
from tensorflow.keras.datasets import imdb
In [2]:
# We use the same dataset as the previous exercise
with open('imdb_mini.pkl','rb') as f:
X_train, y_train, X_test, y_test = pickle.load(f)
In [3]:
# Similar to the previous exercise, we will pre-preprocess our review sequences
# We fix the vocabulary size to 5000 because our custom
# dataset was curated with that
vocabulary_size = 5000
# Max word length for each review will be 500
max_words = 500
# we set the embedding size to 32
embedding_size=32
# Pre-padding sequences to max_words lenth
X_train = sequence.pad_sequences(X_train, maxlen=max_words,padding='pre')
X_test = sequence.pad_sequences(X_test, maxlen=max_words,padding='pre')
In [4]:
# We create the mapping between words and sequences
word2id = imdb.get_word_index()
# We need to adjust the mapping by 3 because of tensorflow.keras preprocessing
# more here: https://stackoverflow.com/questions/42821330/restore-original-text-from-keras-s-imdb-dataset
word2id = {k:(v+3) for k,v in word2id.items()}
word2id["" ] = 0
word2id["" ] = 1
word2id["" ] = 2
word2id["" ] = 3
# Reversing the key,value pair will give the id2word
id2word = {i: word for word, i in word2id.items()}
In [40]:
### edTest(test_chow1) ###
# Submit an answer choice as a string below (eg. if you choose option A, put 'A')
answer1 = '___'
In [5]:
# Complete the helper code below to build the Pavlos Recurrent Unit
# We do this by building a PRU cell unit
# which we can wrap around tf.keras.layers.RNN
# Read more here on layer subclassing https://keras.io/guides/making_new_layers_and_models_via_subclassing/
class PRUCell(tf.keras.layers.Layer):
def __init__(self,units,**kwargs):
self.units = units
self.state_size = units
self.activation = tf.math.tanh
self.recurrent_activation = tf.math.sigmoid
super(PRUCell, self).__init__(**kwargs)
# In the build function we initialize the weights
# Which will be used for training
def build(self, input_shape):
# Initializing weights for candidate Ht
## W_{XH}
self.kernel_h = self.add_weight(shape=(input_shape[-1], self.units),
initializer='uniform',
name='kernel')
## W_{HH}
self.recurrent_kernel_h = self.add_weight(
shape=(self.units, self.units),
initializer='uniform',
name='recurrent_kernel')
# Initializing weights for PP gate
## W_{XPP}
self.kernel_pp = self.add_weight(shape=(input_shape[-1], self.units),
initializer='uniform',
name='PP_kernel')
## W_{HPP}
self.recurrent_kernel_pp = self.add_weight(
shape=(self.units, self.units),
initializer='uniform',
name='PP_recurrent_kernel')
self.built = True
# Note that we do not include a bias term for ease of understanding
def call(self, inputs, states):
## inputs: X_t
## states: h_{t-1}
## self.XXXX contains the weights (see above)
# Previous output comes from states tuple, H_{t-1}
prev_output = states[0]
# First we compute the PPgate
PP_XW = K.dot(___, ___)
PP_HV = K.dot(___, ___)
PPgate = self.recurrent_activation( ___ + ___)
# Now we use the PPgate as per the equation for candidate Ht
nn_XW = K.dot(___, ___)
dotted_output = ___*___
nn_HV = K.dot(dotted_output, ___)
output = self.activation(___ + ___)
return output, [output]
In [6]:
# Now that we have our PRU RNN
# we will build a simple model similar to the previous exercise
# We will use the functional API to do this
hidden_state_units = 5
# Specify the input dimensions HINT: It is max_words
inputs = Input(shape=(max_words,))
# The inputs will go in an embedding layer
embedding = Embedding(vocabulary_size,embedding_size, input_length=max_words)(inputs)
# The embeddings will be an input to the PRU layer
cell = PRUCell(hidden_state_units)
layer = RNN(cell)
hidden_output = layer(embedding)
# The output from the PRU block will go in a dense layer
output = Dense(1, activation='sigmoid')(hidden_output)
# Connecting the architecture using tf.keras.models.Model
pru_model = Model(inputs=inputs, outputs=output)
# Get the summary to see if your model is built correctly
print(pru_model.summary())
In [26]:
### edTest(test_chow2) ###
# Submit an answer choice as a string below (eg. if you choose option A, put 'A')
answer2 = '____'
In [18]:
# Compile the model using 'binary_crossentropy' loss
# and 'adam' optimizer, additionally add 'accuracy' metric
pru_model.compile(___)
In [19]:
# Train the model with appropriate batch size and number of epochs
batch_size = 256
num_epochs = 3
pru_model.fit(___)
Out[19]:
In [33]:
# Evaluate the model on the custom test set and report the
accuracy = pru_model.evaluate(X_test, y_test)[1]
print(f'The accuracy for the PRU model is {100*accuracy:.2f}%')
🍲 Adding the bias to the PRU model¶
Go back and add a bias term to the PRUCell (one for the PPGate and the other for $H_t$)
Does your model performance improve under the same training conditions?
In [27]:
### edTest(test_chow3) ###
# Type your answer within in the quotes given
answer3 = '___'