Key Word(s): ??
Title :¶
Vanishing Gradients
Description :¶
The goal of this exercise is to understand the vanishing gradient problem in training RNNs and using various methods to improve training.
In order to do this exercise, we will use the IMDB movie review dataset to perform sentiment analysis.
Your final comparison for the trace plot may look something like this:
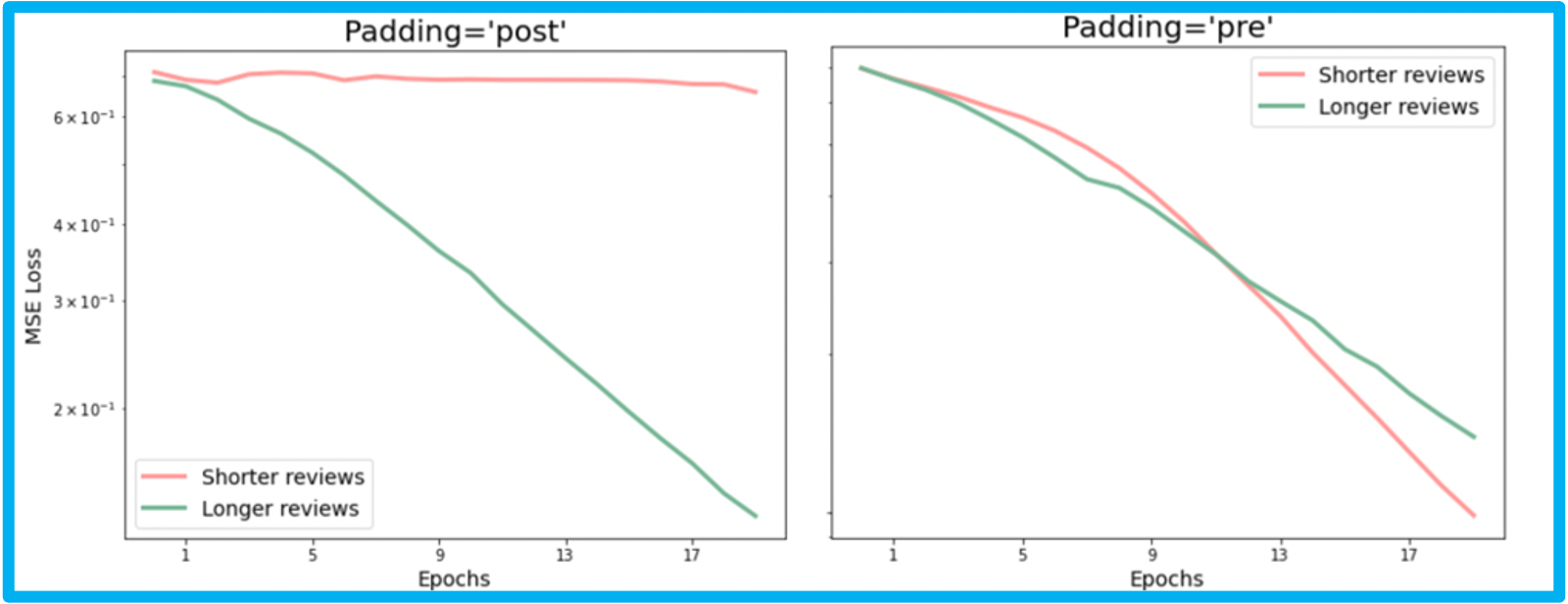
Instructions:¶
- Read the IMDB dataset from the helper code given.
- Take a quick look at your training inputs and labels.
- Pad the values to a fix number
max_wordsin-order to have sequences of the same size. - First post pad the inputs with
padding='post'i.e sequences smaller thanmax_wordswill be followed by zero padding. - Build, compile and fit a Vanilla RNN and evaluate it on the test set.
- Now refit the model, but this time post pad the inputs with
padding='pre' - Again evaluate the model performance on the test set.
- Finally, rebuild a model with the Gated Recurrent Unit and fit and evaluate on the training and test set respectively.
- Compare the performance of all three models similar to the table above.
Hints:¶
tensorflow.keras.preprocessing.sequence.pad_sequences() Pad the sequences to same length - pre/post.
Vanilla RNNs¶
We will use Vanilla Recurrent Neural Networks to perform sentiment analysis in
tensorflow.keras using imdb movie reviews dataset.
The dataset is a subset consisting of 10,000 reviews in the training and test set each. see here for more info
# Import required libraries
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense,GRU
import pickle
import numpy as np
import matplotlib.pyplot as plt
from prettytable import PrettyTable
from pprint import pprint
# We fix a vocabulary size of 5000
# Use the code below to call a small subset of the imdb dataset
# We keep the vocabulary size fixed because it was used to curate the sub-dataset
vocabulary_size = 5000
with open('imdb_mini.pkl','rb') as f:
X_train, y_train, X_test, y_test = pickle.load(f)
Inspect a sample review and its label¶
# Run the code below to see the first tokenized review and the label
print('---review---')
print(X_train[0])
print('---label---')
print(y_train[0])
# You can get the word2id mapping by
# using the imdb.get_word_index() function
word2id = imdb.get_word_index()
# We need to adjust the mapping by 3 because of tensorflow.keras preprocessing
# more here: https://stackoverflow.com/questions/42821330/restore-original-text-from-keras-s-imdb-dataset
word2id = {k:(v+3) for k,v in word2id.items()}
word2id["" ] = 0
word2id["" ] = 1
word2id["" ] = 2
word2id["" ] = 3
# Reversing the key,value pair will give the id2word
id2word = {i: word for word, i in word2id.items()}
pprint('---review with words---')
pprint(" ".join([id2word[i] for i in X_train[0]]))
pprint('---label---')
pprint(y_train[0]);
Maximum review length and minimum review length
### edTest(test_chow1) ###
# Submit an answer choice as a string below (eg. if you choose option C, put 'C')
answer1 = '___'
# For training we need our sequences to be of fixed length, but the reviews
# are of different sizes
print(f'Maximum review length: {len(max([i for i in X_train]+[i for i in X_test], key=len))}')
print(f'Minimum review length: {len(min([i for i in X_train]+[i for i in X_test], key=len))}')
# We also create two indices for short and long reviews
# we will use this later
idx_short = [i for i,val in enumerate(X_train) if len(val)<100]
idx_long = [i for i,val in enumerate(X_train) if len(val)>500]
Pad sequences¶
In order to feed this data into our RNN, all input documents must have the same length. We will limit
the maximum review length to max_words by truncating longer reviews and padding shorter reviews. We
can accomplish this using the pad_sequences() function in tensorflow.keras. For now,
set max_words to 500.
⏸ If we use post-padding on a sequence, the new sequence is"¶
A. "Padded with zeros before the start of original sequence"¶
B. "Padded with zeros after the end of the original sequence"¶
C. "Padded with ones before the start of original sequence"¶
D. "Padded with ones after the end of the original sequence"¶
### edTest(test_chow2) ###
# Submit an answer choice as a string below (eg. if you choose option C, put 'C')
answer2 = '___'
# We will clip large reviews and pad smaller reviews to 500 words
max_words = 500
# We can pad the smaller sequences with 0s before, or after.
# This choice can severely affect network performance
# In the first case we, will pad after the sequence
# Please utilize sequence.pad_sequences()
postpad_X_train = ___
postpad_X_test = ___
RNN model for sentiment analysis¶
We build the model architecture in the code cell below. We have imported some layers from tensorflow.keras
that you might need but feel free to use any other layers / transformations you like.
Remember that our input is a sequence of words (technically, integer word IDs) of maximum length = max_words, and our output is a binary sentiment label (0 or 1).
def model_maker(summary=True,gru=False):
# One layer RNN model with 32 rnn cells
embedding_size=32
model=Sequential()
model.add(Embedding(vocabulary_size, embedding_size, input_length=max_words))
# We can specify if we want the GRU cell or the vanilla RNN cell
if gru:
model.add(GRU(32))
else:
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
if summary:
print(model.summary())
# model compile step
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
Trace Plot analysis¶
We expect the postpadded model to perform train slowly because of vanishing gradients. Let us investigate the cause by training two models,
- One with shorter reviews (that were post padded) using
idx_short - The other with longer reviews (that were truncated) using
idx_long
# We build two new models with vanilla RNNs
model_short = model_maker(summary=False)
model_long = model_maker(summary=False)
# First we train `model_short` with short reviews
# set epochs to 10
X_short = ___
y_short = ___
epochs = ___
history_short = model_short.fit(___, ___, epochs=epochs,batch_size=640,verbose=0);
# Then we train `model_long` with short reviews
X_long = ___
y_long = ___
history_long = model_long.fit(___,___, epochs=epochs,batch_size=640,verbose=0);
### edTest(test_chow2_1) ###
X_short_shape, y_short_shape = X_short.shape, y_short.shape
X_long_shape, y_long_shape = X_long.shape, y_long.shape
print(X_short_shape, y_short_shape,X_long_shape, y_long_shape)
# Helper function to plot the data
# Plot the MSE of the model
plt.rcParams["figure.figsize"] = (8,6)
plt.title("Padding='post'",fontsize=20)
plt.semilogy(history_short.history['loss'], label='Shorter reviews', color='#FF9A98', linewidth=3)
plt.semilogy(history_long.history['loss'], label='Longer reviews', color='#75B594', linewidth=3)
plt.legend()
# Set the axes labels
plt.xlabel('Epochs',fontsize=14)
plt.xticks(range(1,epochs,4))
plt.ylabel('MSE Loss',fontsize=14)
plt.legend(fontsize=14)
plt.show()

Pre-padding sequences¶
As we can see, the vanishing gradient problem is real and can severely affect the training of our network. The short review network negligibly trains, whereas the longer review model trains very well. To counter this, we will now pre-pad the shorter sequences.
# We can pre-pad by using `sequence.pad_sequences` with `padding='pre'`
max_words = 500
prepad_X_train = ___
prepad_X_test = ___
Trace Plot - Take 2¶
Again, we investigate the trace plots for the two categories, but this time, with pre-padding
# Reinitializing the models for the two categories
model_short = model_maker(summary=False)
model_long = model_maker(summary=False)
# Again we train `model_short` with short reviews
X_short = ___
y_short = ___
epochs = 10
history_short = model_short.fit(___, ___, epochs=epochs,batch_size=640,verbose=0);
# Then we train `model_long` with short reviews
X_long = ___
y_long = ___
history_long = model_long.fit(___, ___, epochs=epochs,batch_size=640,verbose=0);
# Helper function to plot the data
# Plot the MSE of the model
plt.rcParams["figure.figsize"] = (8,6)
plt.title("Padding='pre'",fontsize=20)
plt.semilogy(history_short.history['loss'], label='Shorter reviews', color='#FF9A98', linewidth=3)
plt.semilogy(history_long.history['loss'], label='Longer reviews', color='#75B594', linewidth=3)
plt.legend()
# Set the axes labels
plt.xlabel('Epochs',fontsize=14)
plt.xticks(range(1,epochs,4))
plt.ylabel('MSE Loss',fontsize=14)
plt.legend(fontsize=14)
plt.show()

🍲 Further improvements¶
We solved the vanishing gradient problem by pre-padding the sequences, but what other design choices can help you improve performance?
### edTest(test_chow3) ###
# Submit your answer as a string below
answer3 = '___'