Title¶
Exercise - Multi-class Classification and PCA
Description¶
This exercise follows more like a lab and is broken into 3 parts (we will reconvene after each part). The 3 parts are:
- Data set exploration and baseline models (graded)
- PCA and PCR (graded)
- Going Further with the dataset (not graded)
Learning Goals¶
In this lab, we will look at how to use PCA to reduce a dataset to a smaller number of dimensions. The goals are:
- Better Understand the multiclass setting
- Understand what PCA is and why it's useful
- Feel comfortable performing PCA on a new dataset
- Understand what it means for each component to capture variance from the original dataset
- Be able to extract the
variance explainedby components - Perform modeling with the PCA components
Hints:¶
sklearn.accuracy_score : Generates a Logistic Regression Model
sklearn.LogisticRegression : Generates a Logistic Regression Model
sklearn.LogisticRegressionCV : Uses CV to perform regularization in Logistic Regression
sklearn.PCA : Create a Principal Component Analysis (PCA) decomposition
Note: This exercise is auto-graded and you can try multiple attempts.
 CS-109A Introduction to Data Science
CS-109A Introduction to Data Science
Lecture 21: More on Classification and PCA¶
Harvard University
Fall 2020
Instructors: Pavlos Protopapas, Kevin Rader, Chris Tanner
Contributors: Kevin Rader, Eleni Kaxiras, Chris Tanner, Will Claybaugh, David Sondak
## RUN THIS CELL TO PROPERLY HIGHLIGHT THE EXERCISES
import requests
from IPython.core.display import HTML
styles = requests.get("https://raw.githubusercontent.com/Harvard-IACS/2018-CS109A/master/content/styles/cs109.css").text
HTML(styles)
Learning Goals¶
In this lab, we will look at how to use PCA to reduce a dataset to a smaller number of dimensions. The goals are:
- Better Understand the multiclass setting
- Understand what PCA is and why it's useful
- Feel comfortable performing PCA on a new dataset
- Understand what it means for each component to capture variance from the original dataset
- Be able to extract the `variance explained` by components
- Perform modelling with the PCA components
%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.linear_model import LogisticRegressionCV
from sklearn.linear_model import LassoCV
from sklearn.metrics import accuracy_score
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
from sklearn.model_selection import train_test_split
Part 0: Introduction¶
What is PCA? PCA is a deterministic technique to transform data to a lowered dimensionality, whereby each feature/dimension captures the most variance possible.
Why do we care to use it?
- Visualizating the components can be useful
- Allows for more efficient use of resources (time, memory)
- Statistical reasons: fewer dimensions -> better generalization
- noise removal / collinearity (improving data quality)
Imagine some dataset where we have two features that are pretty redundant. For example, maybe we have data concerning elite runners. Two of the features may include VO2 max and heartrate. These are highly correlated. We probably don't need both, as they don't offer much additional information from each other. Using a great visual example from online, let's say that this unlabelled graph (always label your axis) represents those two features:
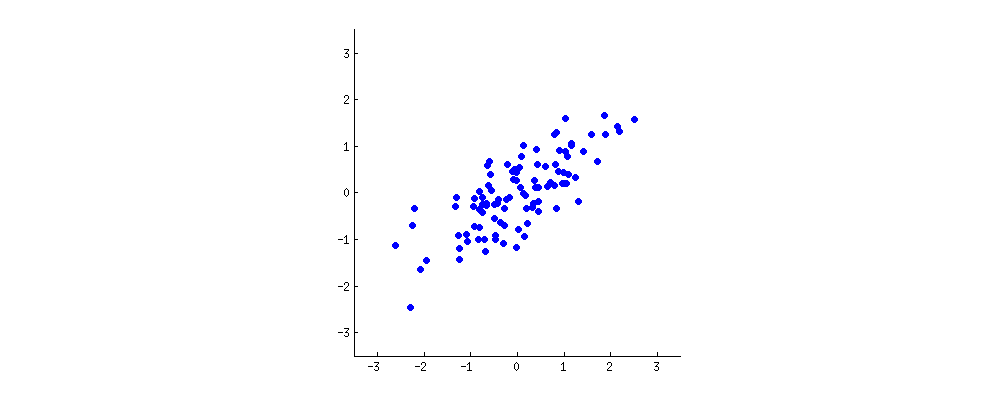
Let's say that this is our entire dataset, just 2 dimensions. If we wish to reduce the dimensions, we can only reduce it to just 1 dimension. A straight line is just 1 dimension (to help clarify this: imagine your straight line as being the x-axis, and values can be somewhere on this axis, but that's it. There is no y-axis dimension for a straight line). So, how should PCA select a straight line through this data?
Below, the image shows all possible projects that are centered in the data:
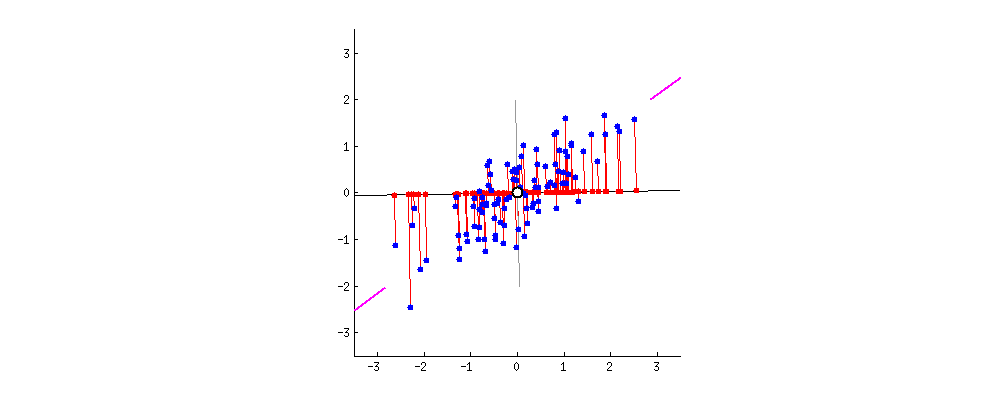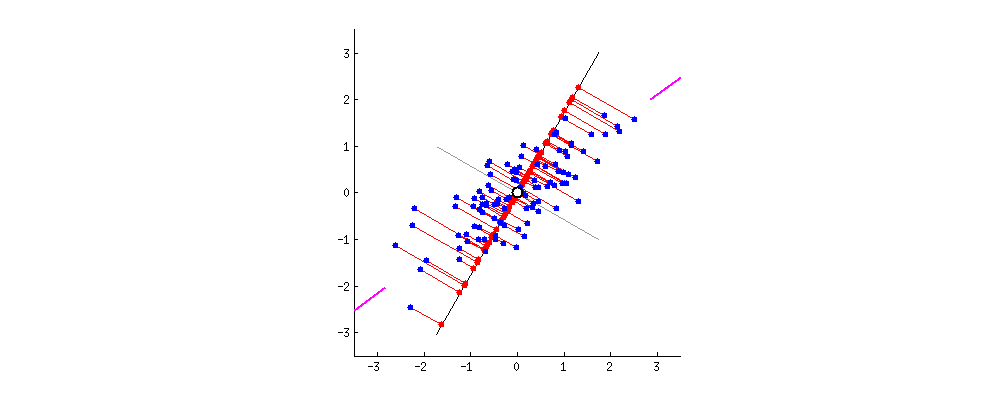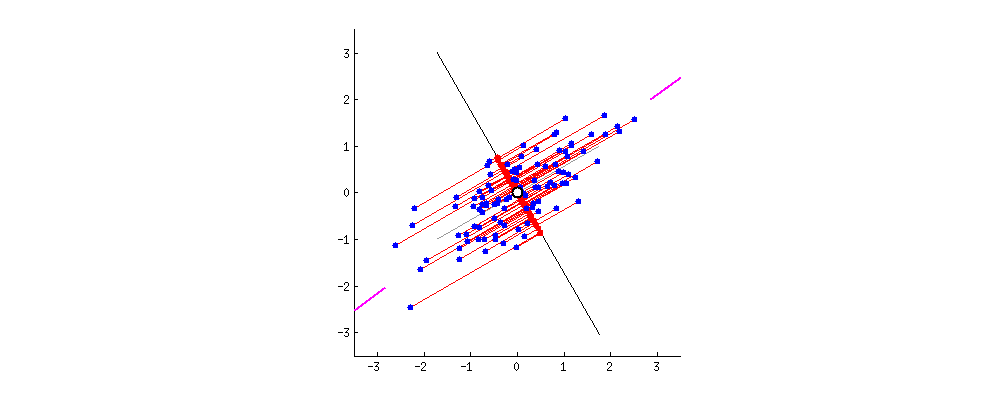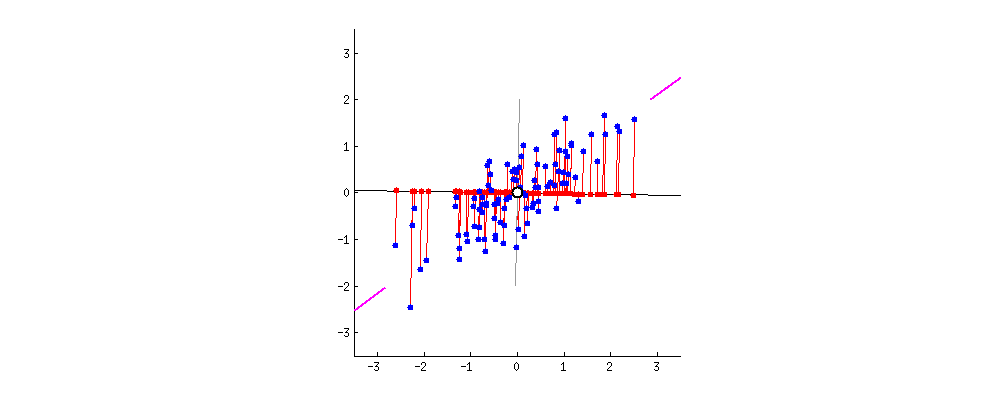
PCA picks the line that:
- captures the most variance possible
- minimizes the distance of the transformed points (distance from the original to the new space)
The animation suggests that these two aspects are actually the same. In fact, this is objectively true, but the proof for which is beyond the scope of the material for now. Feel free to read more at this explanation and via Andrew Ng's notes.
In short, PCA is a math technique that works with the covariance matrix -- the matrix that describes how all pairwise features are correlated with one another. Covariance of two variables measures the degree to which they moved/vary in the same directin; how much one variable affects the other. A positive covariance means they are positively related (i.e., x1 increases as x2 does); negative means negative correlation (x1 decreases as x2 increases).
In data science and machine learning, our models are often just finding patterns in the data this is easier if the data is spread out across each dimension and for the data features to be independent from one another (imagine if there's no variance at all. We couldn't do anything). Can we transform the data into a new set that is a linear combination of those original features?
PCA finds new dimensions (set of basis vectors) such that all the dimensions are orthogonal and hence linearly independent, and ranked according to the variance (eigenvalue). That is, the first component is the most important, as it captures the most variance.
Part 1a: The Wine Quality Dataset¶
Imagine that a wine sommelier has tasted and rated 1,000 distinct wines, and now that she's highly experienced, she is curious if she can more efficiently rate wines without even trying them. That is, perhaps her tasting preferences follow a pattern, allowing her to predict the rating a new wine without even trying it!
The dataset contains 11 chemical features, along with a quality scale from 1-10; however, only values of 3-9 are actually used in the data. The ever-elusive perfect wine has yet to be tasted.
NOTE: While this dataset involves the topic of alcohol, we, the CS109A staff, along with Harvard at large is in no way encouraging alcohol use, and this example should not be intrepreted as any endorsement for such; it is merely a pedagogical example. I apologize if this example offends anyone or is off-putting.¶
Read-in and checking¶
First, let's read-in the data and verify it:
wines_df = pd.read_csv("data/wines.csv")
wines_df.head()
wines_df.describe()
For this exercise, let's say that the wine expert is curious if she can predict, as a rough approximation, the categorical quality -- bad, average, or great. Let's define those categories as follows:
badis when for wines that have a quality <= 5averageis when a wine has a quality of 6greatis when a wine has a quality of >= 7
Q1.1 For sanity, let's see how many wines will end up in each quality category (create the barplot)
counts = np.unique(wines_df['quality'],return_counts=True)
### use seaborn to create a barplot
sns.barplot(x=___,y=___);
##### copy the original data so that we're free to make changes
wines_df_recode = wines_df.copy()
# use the 'cut' function to reduce a variable down to the aforementioned bins (inclusive boundaries)
wines_df_recode['quality'] = pd.cut(wines_df_recode['quality'],[0,5,6,10], labels=[0,1,2])
wines_df_recode.loc[wines_df_recode['quality'] == 1]
# drop the un-needed columns
x_data = wines_df_recode.drop(['quality'], axis=1)
y_data = wines_df_recode['quality']
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=.2, random_state=8, stratify=y_data)
# previews our data to check if we correctly constructed the labels (we did)
print(wines_df['quality'].head())
print(wines_df_recode['quality'].head())
y_data.value_counts()
Now that we've split the data, let's look to see if there are any obvious patterns (correlations between different variables).
from pandas.plotting import scatter_matrix
scatter_matrix(wines_df_recode, figsize=(30,20));
It looks like there aren't any particularly strong correlations among the predictors (maybe total sulfur dioxide and free sulfur dioxide) so we're safe to keep them all.
Part 1b: Baseline Prediction Models¶
Before we do anything too fancy, it's always best to start with something simple.
Baseline¶
The baseline estimate is barely a model -- it simple returns the single label/class occurs the most often (in the training data). In other words, whichever label/class is most popular, it will always preduct that as its answer, completely independent of any x-data. Above, we saw that the most popular label was average, represented by 432 of our 1,000 wines. Thus, our MLE should yield average for all inputs:
baseline_class = y_data.value_counts().idxmax()
baseline_train_accuracy = len(y_train.loc[y_train == baseline_class]) / len(y_train)
baseline_test_accuracy = len(y_test.loc[y_test == baseline_class]) / len(y_test)
scores = [[baseline_train_accuracy, baseline_test_accuracy]]
names = ['baseline']
df_results = pd.DataFrame(scores, index=names, columns=['Train Accuracy', 'Test Accuracy'])
df_results
Baseline gives a predictive accuracy is 43.3% on the test set. Hopefully we can do better than this.
Logistic Regression¶
Logistic regression is used for predicting categorical outputs, which is exactly what our task concerns. So, let's create a multiclass logistic regression model (ovr: one-vs.-rest):
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=1000000, solver='lbfgs', multi_class='ovr', max_iter=10000).fit(x_train,y_train)
print("Coefficients:", lr.coef_)
print("Intercepts:", lr.intercept_)
Q1.2 What is stored in .coef_ and .intercept_? Why are there so many of them?
your answer here
Q1.3 Determine measure its performance as measured by classific ation accuracy:
### edTest(test_acc) ###
lr_train_accuracy = lr.score(___,___)
lr_test_accuracy = lr.score(___,___)
# appends results to our dataframe
names.append('Logistic Regression')
scores.append([lr_train_accuracy, lr_test_accuracy])
df_results = pd.DataFrame(scores, index=names, columns=['Train Accuracy', 'Test Accuracy'])
df_results
Yay, that's better than our baseline performance. Can we do better with cross-validation?
Part 1c: Tuning our Prediction Model¶
Summary¶
- Logistic regression extends OLS to work naturally with a dependent variable that's only ever 0 and 1.
- In fact, Logistic regression is even more general and is used for predicting the probability of an example belonging to each of $N$ classes.
- The code for the two cases is identical and just like
LinearRegression:.fit,.score, and all the rest - Significant predictors does not imply that the model actually works well. Signifigance can be driven by data size alone.
- The data aren't enough to do what we want
Warning: Logistic regression tries to hand back valid probabilities. As with all models, you can't trust the results until you validate them- if you're going to use raw probabilities instead of just predicted class, take the time to verify that if you pool all cases where the model says "I'm 30% confident it's class A" 30% of them actually are class A.
Q1.4 Use LogisticRegressionCV to build a better tuned ovr (lasso-based) model based on all of these predictors.
### edTest(test_logitCV) ###
logit_regr_lasso = LogisticRegressionCV(solver='liblinear', multi_class=___, penalty=___, max_iter=___, cv=10)
logit_regr_lasso.fit(x_train,y_train) # fit
y_train_pred_lasso = ___ # predict the test set
y_test_pred_lasso = ___ # predict the test set
train_score_lasso = ___ # get train accuracy
test_score_lasso = ___ # get test accuracy
names.append('Logistic Regression w/ CV + Lasso')
scores.append([train_score_lasso, test_score_lasso])
df_results = pd.DataFrame(scores, index=names, columns=['Train Accuracy', 'Test Accuracy'])
df_results
Q1.5: Hmm, cross-validation didn't seem to offer much improved results. Is this correct? Is it possible for cross-validation to not yield much better results than non-cross-validation? If so, why is that happening here? What else should we consider?
your answer here
Part 2: Dimensionality Reduction¶
In attempt to improve performance, we may wonder if some of our features are redundant and are posing difficulties for our logistic regression model.
Q2.1: Let's PCA decompose our predictors to shrink the problem down to 2 dimensions (with as little loss as possible) and see if that gives us a clue about what makes this problem tough.
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
num_components = 2
# scale the datasets
scale_transformer = StandardScaler(copy=True).fit(x_train)
x_train_scaled = scale_transformer.transform(x_train)
x_test_scaled = scale_transformer.transform(x_test)
# reduce dimensions
pca_transformer = PCA(___).fit(___)
x_train_2d = pca_transformer.transform(___)
x_test_2d = pca_transformer.transform(___)
print(x_train_2d.shape)
x_train_2d[0:5,:]
NOTE:
- Both scaling and reducing dimension follow the same pattern: we fit the object to the training data, then use .transform() to convert the training and test data. This ensures that, for instance, we scale the test data using the training mean and variance, not its own mean and variance
- We need to equalize the variance of each feature before applying PCA; otherwise, certain dimensions will dominate the scaling. Our PCA dimensions would just be the features with the largest spread.
Q2.2: Why didn't we scale the y-values (class labels) or transform them with PCA? Is this a mistake?
your answer here
Q2.3: Our data only has 2 dimensions/features now. What do these features represent?
# your code here
your answer here
Since our data only has 2 dimensions now, we can easily visualize the entire dataset. If we choose to color each datum with respect to its associated label/class, it allows us to see how separable the data is. That is, it gives an indication as to how easy/difficult it is for a model to fit the new, transformed data.
Q2.4: Create the scatterplot with color-coded points for the 3 classes of wine quaslity, and put PCA vector 1 on the x-axis and PCA vector 2 on the y-axis.
# notice that we set up lists to track each group's plotting color and label
colors = ['r','c','b']
label_text = ["Bad Wines", "Average Wines", "Great Wines"]
# and we loop over the different groups
for cur_quality in [0,1,2]:
cur_df = x_train_2d[y_train==cur_quality]
plt.scatter(___, ___, c = colors[cur_quality], label=label_text[cur_quality])
# all plots need labels
plt.xlabel("PCA Dimension 1")
plt.ylabel("PCA Dimention 2")
plt.legend();
Well, that gives us some idea of why the problem is difficult! The bad, average, and great wines are all on top of one another. Not only are there few great wines, which we knew from the beginning, but there is no line that can easily separate the classes of wines.
Q2.5:
- What critique can you make against the plot above? Why does this plot not prove that the different wines are hopelessly similar?
- The wine data we've used so far consist entirely of continuous predictors. Would PCA work with categorical data?
- Looking at our PCA plot above, we see something peculiar: we have two disjoint clusters, both of which have immense overlap in the qualities of wines.What could cause this? What does this mean?
your answer here
Let's plot the same PCA'd data, but let's color code them according to if the wine is red or white
# notice that we set up lists to track each group's plotting color and label
colors = ['r','c','b']
label_text = ["Reds", "Whites"]
# and we loop over the different groups
for cur_color in [0,1]:
cur_df = x_train_2d[x_train['red']==cur_color]
plt.scatter(___, ___, c = colors[cur_color], label=label_text[cur_color])
# all plots need labels
plt.xlabel("PCA Dimension 1")
plt.ylabel("PCA Dimention 2")
plt.legend();
Q2.6: Wow. Look at that separation. Too bad we aren't trying to predict if a wine is red or white. Does this graph help you answer our previous question? Does it change your thoughts?
your answer here
Part 2b. Evaluating PCA: Variance Explained and Predictions¶
One of the criticisms we made of the PCA plot was that it's lost something from the original data. Heck, we're only using 2 dimensions, we it's perfectly reasonable and expected for us to lose some information -- our goal was that the information we were discarding was noise.
Let's investigate how much of the original data's structure the 2-D PCA captures. We'll look at the explained_variance_ratio_ portion of the PCA fit. This lists, in order, the percentage of the x data's total variance that is captured by the nth PCA dimension.
var_explained = pca_transformer.explained_variance_ratio_
print("Variance explained by each PCA component:", var_explained)
print("Total Variance Explained:", np.sum(var_explained))
The first PCA dimension captures 33% of the variance in the data, and the second PCA dimension adds another 20%. Together, we've captured about half of the total variation in the training data with just these two dimensions. So far, we've used PCA to transform our data, we've visualized our newly transformed data, and we've looked at the variance that it captures from the original dataset. That's a good amount of inspection; now let's actually use our transformed data to make predictions.
Q2.7 Use Logistic Regression (with and without cross-validation) on the PCA-transformed data. Do you expect this to outperform our original accuracy? What are your results? Does this seem reasonable?
### edTest(test_lrPCA) ###
# do the non-CV approach here (create CV on your own if you'd like)
lr_pca = ___
lr_pca_train_accuracy = ___
lr_pca_test_accuracy = ___
names.append('Logistic Regression w/ PCA')
___
___
df_results
We're only using 2 dimensions. What if we increase our data to the full PCA components?
Q2.8: How can we incorporate the type of wine (Red vs. White) into this analysis (hink of at least 2 different approaches)? Can these both approaches be used for the PCA and non-PCA models?
Part 3: Going further with PCA¶
Q3.1:
Hint: np.cumsum stands for 'cumulative sum', so np.cumsum([1,3,2,-1,2]) is [1,4,6,5,7]
#your code here
The plot above can be used to inform of us when we reach diminishing returns on variance explained. That is, the 'elbow' of the line is probably an ideal number of dimensions to use, at least with respect to the amount of variance explained.
Q3.2 Looking at your graph, what is the 'elbow' point / how many PCA components do you think we should use? Does this number of components agree with the cross-validated predictive performance of the PCR? Explain.
your answer here
Part 3b: PCA Debriefing:¶
- PCA maps a high-dimensional space into a lower dimensional space.
- The PCA dimensions are ordered by how much of the original data's variance they capture
- There are other cool and useful properties of the PCA dimensions (orthogonal, etc.). See a textbook.
- PCA on a given dataset always gives the same dimensions in the same order.
- You can select the number of dimensions by fitting a big PCA and examining a plot of the cumulative variance explained.
PCA is not guaranteed to improve predictive performance at all. As you've learned in class now, none of our models are guaranteed to always outperform others on all datasets; analyses are a roll of the dice. The goal is to have a suite of tools to allow us to gather, process, disect, model, and visualize the data -- and to learn which tools are better suited to which conditions. Sometimes our data isn't the most conducive to certain tools, and that's okay.
What can we do about it?
- Be honest about the methods and the null result. Lots of analyses fail.
- Collect a dataset you think has a better chance of success. Maybe we collected the wrong chemical signals...
- Keep trying new approaches. Just beware of overfitting the data you're validating on. Always have a test set locked away for when the final model is built.
- Change the question. Maybe something you noticed during analysis seems interesting or useful (classifying red versus white). But again, you the more you try, the more you might overfit, so have test data locked away.
- Just move on. If the odds of success start to seem small, maybe you need a new project.