Key Word(s): Regularization, Neural Networks, Data Augmentation, Weight Decay, Dropout
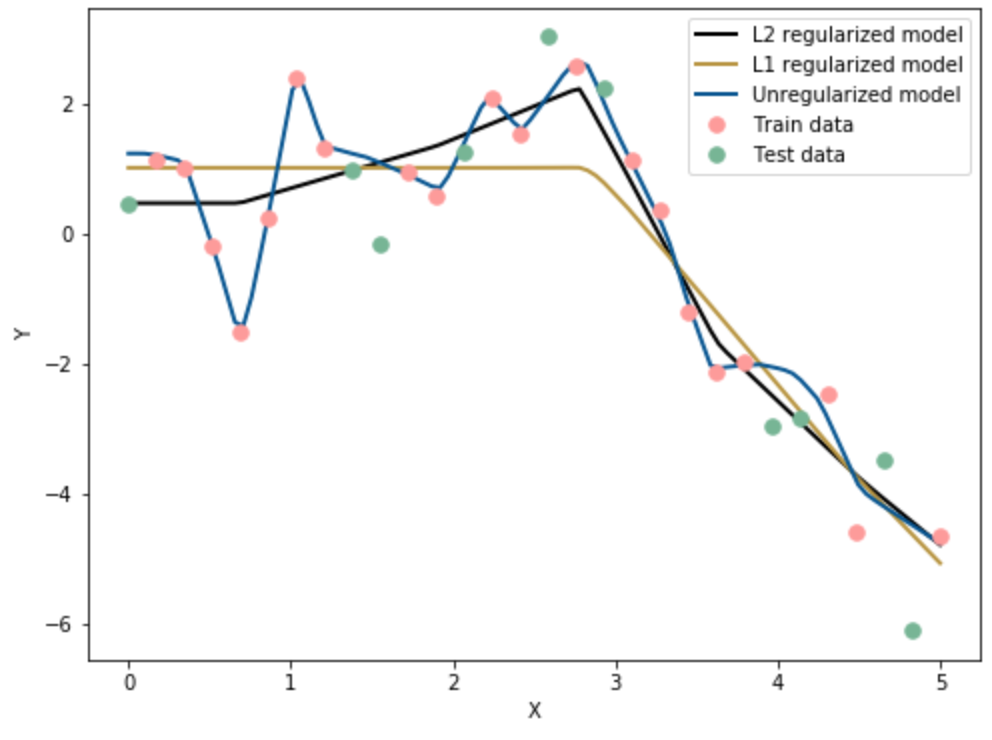
NOTE: This graph is only a sample (including the mindchow part). The data will be the same, the model predictions will depend on your regularization parameters.
Instructions:¶
- Generate the predictor and response data using the helper code given.
- Split the data into train and test sets.
- Visualise the split data using the helper code.
- Build a simple neural network with 5 hidden layers with 100 neurons each. This network has no regularization.
- Compile the model with MSE as the loss.
- Fit the model on the training data and save the history.
- Use the helper code to visualise the MSE of the train and test data with respect to the epochs.
- Predict on the entire data.
- Use the helper function to plot the predictions along with the generated data.
- Repeat steps 4 to 8 with a neural network with L2 regularization. Try with a range of 1e-3 to 1e-1.
Hints:¶
Use the Dense layer to regularize using l2 and l1 regularization. More details can be found here.
tf.keras.sequential() : A sequential model is for a plain stack of layers where each layer has exactly one input tensor and one output tensor.
tf.keras.optimizers() : An optimizer is one of the two arguments required for compiling a Keras model
model.add() : Adds layers to the model.
model.compile() : Compiles the layers defined into a neural network
model.fit() : Fits the data to the neural network
model.predict() : Used to predict the values given the model
history() : The history object is returned from calls to the fit() function used to train the model. Metrics are stored in a dictionary in the history member of the object returned.
tf.keras.regularizers.L2() : A regularizer that applies a L2 regularization penalty.
# Import the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from sklearn.metrics import mean_squared_error
from tensorflow.keras import optimizers
from tensorflow.keras import regularizers
from sklearn.model_selection import train_test_split
np.random.seed(0)
tf.random.set_seed(0)
%matplotlib inline
# Use the helper code below to generate the data
# Defines the number of data points to generate
num_points = 30
# Generate predictor points (x) between 0 and 5
x = np.linspace(0,5,num_points)
# Generate the response variable (y) using the predictor points
y = x * np.sin(x) + np.random.normal(loc=0, scale=1, size=num_points)
# Generate data of the true function y = x*sin(x)
# x_b will be used for all predictions below
x_b = np.linspace(0,5,100)
y_b = x_b*np.sin(x_b)
# Split the data into train and test sets with .33 and random_state = 42
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=42)
# Plot the train data
plt.rcParams["figure.figsize"] = (10,8)
plt.plot(x_train,y_train, '.', label='Train data', markersize=15, color='#FF9A98')
# Plot the test data
plt.plot(x_test,y_test, '.', label='Test data', markersize=15, color='#75B594')
# Plot the true data
plt.plot(x_b, y_b, '-', label='True function', linewidth=3, color='#5E5E5E')
# Set the axes labels
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()

Begin with an unregularized NN¶
# Building an unregularized NN.
# Initialise the NN, give it an appropriate name for the ease of reading
# The FCNN has 5 layers, each with 100 nodes
model_1 = models.Sequential(name='Unregularized')
# Add 5 hidden layers with 100 neurons each
model_1.add(layers.Dense(100, activation='tanh', input_shape=(100,)))
model_1.add(layers.Dense(100, activation='relu'))
model_1.add(layers.Dense(100, activation='relu'))
model_1.add(layers.Dense(100, activation='relu'))
model_1.add(layers.Dense(100, activation='relu'))
# Add the output layer with one neuron
model_1.add(layers.Dense(1, activation='linear'))
# View the model summary
model_1.summary()
# Compile the model with MSE as loss and Adam optimizer with learning rate as 0.001
model_1.compile(___)
# Save the history about the model after fitting on the train data
# Use 0.2 as the validation split with 1500 epochs and batch size of 10
history_1 = ___
# Helper function to plot the data
# Plot the MSE of the model
plt.rcParams["figure.figsize"] = (10,8)
plt.title("Unregularized model")
plt.semilogy(history_1.history['loss'], label='Train Loss', color='#FF9A98')
plt.semilogy(history_1.history['val_loss'], label='Validation Loss', color='#75B594')
plt.legend()
# Set the axes labels
plt.xlabel('Epochs')
plt.ylabel('Log MSE Loss')
plt.legend()
plt.show()
# Use the model above to predict for x_b (used exclusively for plotting)
y_pred = ___
# Use the model above to predict for x_text
y_pred_test = ___
# Compute the test MSE
mse = ___
# Use the helper code to plot the predicted data
plt.rcParams["figure.figsize"] = (10,8)
plt.plot(x_b, y_pred, label = 'Unregularized model', color='#5E5E5E', linewidth=3)
plt.plot(x_train,y_train, '.', label='Train data', markersize=15, color='#FF9A98')
plt.plot(x_test,y_test, '.', label='Test data', markersize=15, color='#75B594')
plt.legend()
plt.show()
# We will now regularise the NN with L2 regularization
# Initialise the NN, give it a different name for the ease of reading
model_2 = models.___
# Add L2 regularization to the model
# Use L2 regularization parameter value of 0.1
___
# Add 5 hidden layers with 100 neurons each
# relu is the activation for all other layers
# Don't forget to include the regularization parameter from above
model_2.add(layers.Dense(___, kernel_regularizer=___ , activation=___, input_shape=___)
___
___
___
___
# Add the output layer with one neuron and linear activation
model_2.add(layers.Dense(___))
# Compile the model with MSE as loss and Adam optimizer with learning rate as 0.001
model_2.compile(___)
# Save the history about the model after fitting on the train data
# Use 0.2 as the validation split with 1500 epochs and batch size of 10
history_2 = ___
# Helper code to plot the MSE of the L2 regularized model
plt.rcParams["figure.figsize"] = (10,8)
plt.title("L2 Regularized model")
plt.semilogy(history_2.history['loss'], label='Train Loss', color='#FF9A98')
plt.semilogy(history_2.history['val_loss'], label='Validation Loss', color='#75B594')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.legend()
plt.show()
# Use the regularised model above to predict for x_b (used exclusively for plotting)
y_l2_regularized_pred = ___
# Use the regularised model above to predict for x_text
y_l2_pred_test = ___
# Compute the test MSE by predicting on the test data
mse_l2 = ___
# Use the helper code to plot the predicted data
# Plotting the predicted data using the L2 regularized model
plt.rcParams["figure.figsize"] = (10,8)
plt.plot(x_b, y_l2_regularized_pred, label='L2 regularized model', color='#5E5E5E', linewidth=3)
# Plotting the predicted data using the unregularized model
plt.plot(x_b, y_pred, label = 'Unregularized model', color='#005493', linewidth=2)
# Plotting the training data
plt.plot(x_train,y_train, '.', label='Train data', markersize=15, color='#FF9A98')
# Plotting the testing data
plt.plot(x_test,y_test, '.', label='Test data', markersize=15, color='#75B594')
# Set the axes labels
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
Mindchow 🍲¶
Try the same with L1 regularization. Compare the three neural networks models. Which one best reduces overfitting? Why do you think so?
Your answer here