Key Word(s): The Data Science Process, Data Science Demo
 CS109A Introduction to Data Science
CS109A Introduction to Data Science
Lecture 1: Example part 2¶
Harvard University
Fall 2020
Instructors: Pavlos Protopapas, Kevin Rader, and Chris Tanner
In [1]:
import sys
import datetime
import numpy as np
import scipy as sp
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from math import radians, cos, sin, asin, sqrt
from sklearn.linear_model import LinearRegression
sns.set(style="ticks")
%matplotlib inline
In [2]:
import os
DATA_HOME = os.getcwd()
if 'ED_USER_NAME' in os.environ:
DATA_HOME = '/course/data'
HUBWAY_STATIONS_FILE = os.path.join(DATA_HOME, 'hubway_stations.csv')
HUBWAY_TRIPS_FILE = os.path.join(DATA_HOME, 'hubway_trips_sample.csv')
In [3]:
hubway_data = pd.read_csv(HUBWAY_TRIPS_FILE, index_col=0, low_memory=False)
hubway_data.head()
Out[3]:
Who? Who's using the bikes?¶
Refine into specific hypotheses:
- More men or more women?
- Older or younger people?
- Subscribers or one time users?
In [4]:
# Let's do some cleaning first by removing empty cells or replacing them with NaN.
# Pandas can do this.
# we will learn a lot about pandas
hubway_data['gender'] = hubway_data['gender'].replace(np.nan, 'NaN', regex=True).values
# we drop
hubway_data['birth_date'].dropna()
age_col = 2020.0 - hubway_data['birth_date'].values
In [5]:
# matplotlib can create a plot with two sub-plots.
# we will learn a lot about matplotlib
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
# find all the unique value of the column gender
# numpy can do this
# we will learn a lot about numpy
gender_counts = np.unique(hubway_data['gender'].values, return_counts=True)
ax[0].bar(range(3), gender_counts[1], align='center', color=['black', 'green', 'teal'], alpha=0.5)
ax[0].set_xticks([0, 1, 2])
ax[0].set_xticklabels(['none', 'male', 'female'])
ax[0].set_title('Users by Gender')
age_col = 2020.0 - hubway_data['birth_date'].dropna().values
age_counts = np.unique(age_col, return_counts=True)
ax[1].bar(age_counts[0], age_counts[1], align='center', width=0.4, alpha=0.6)
ax[1].axvline(x=np.mean(age_col), color='red', label='average age')
ax[1].axvline(x=np.percentile(age_col, 25), color='red', linestyle='--', label='lower quartile')
ax[1].axvline(x=np.percentile(age_col, 75), color='red', linestyle='--', label='upper quartile')
ax[1].set_xlim([1, 90])
ax[1].set_xlabel('Age')
ax[1].set_ylabel('Number of Checkouts')
ax[1].legend()
ax[1].set_title('Users by Age')
plt.tight_layout()
plt.savefig('who.png', dpi=300)

Challenge¶
There is actually a mistake in the code above. Can you find it?
Soon you will be skillful enough to answers many "who" questions
Where? Where are bikes being checked out?¶
Refine into specific hypotheses:
- More in Boston than Cambridge?
- More in commercial or residential?
- More around tourist attractions?
In [6]:
# using pandas again to read the station locations
station_data = pd.read_csv(HUBWAY_STATIONS_FILE, low_memory=False)[['id', 'lat', 'lng']]
station_data.head()
Out[6]:
In [7]:
# Sometimes the data is given to you in pieces and must be merged!
# we want to combine the trips data with the station locations. pandas to the rescue...
hubway_data_with_gps = hubway_data.join(station_data.set_index('id'), on='strt_statn')
hubway_data_with_gps.head()
Out[7]:
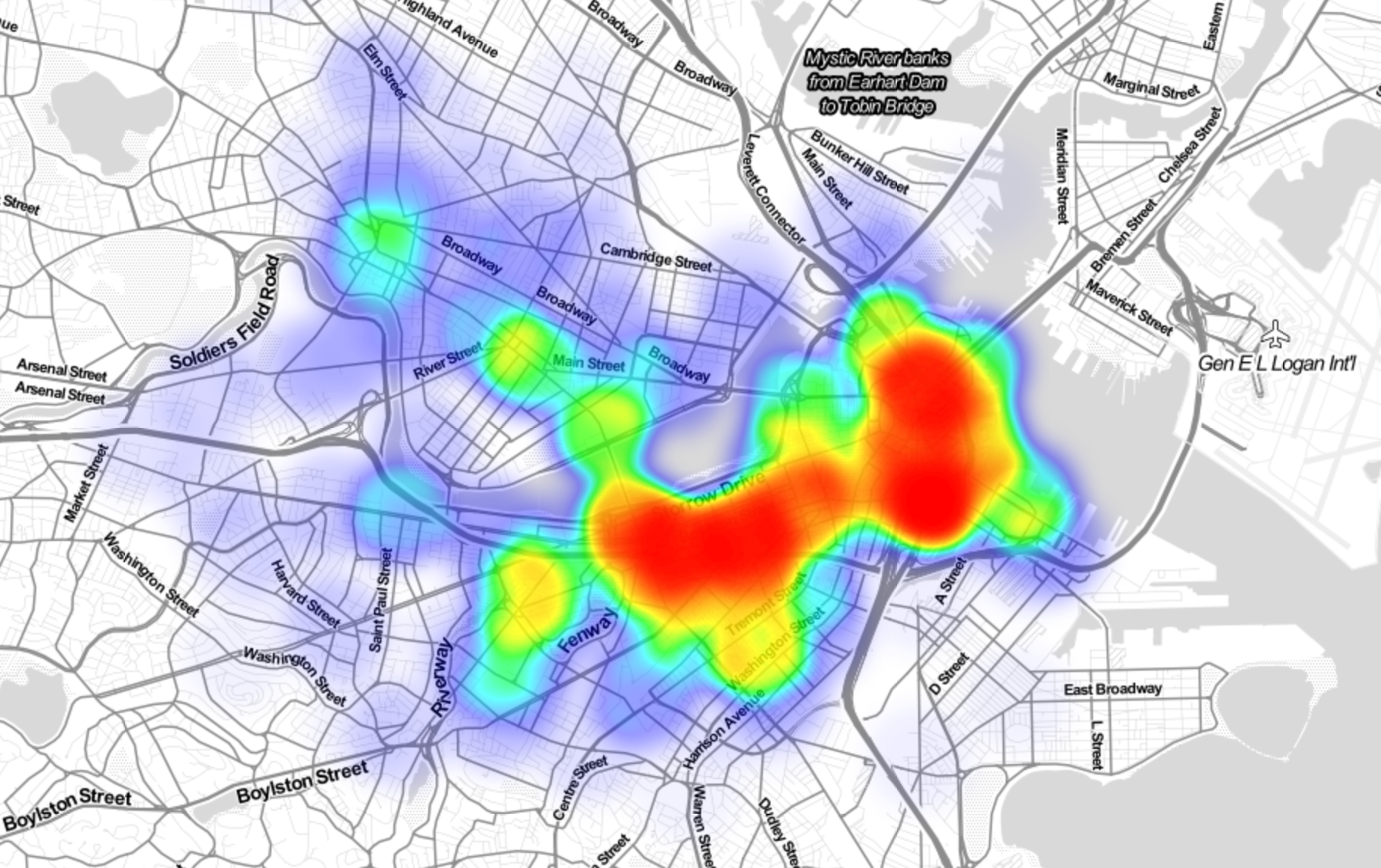
OK - we cheated above and we skip some of the code which generated this plot.
When? When are the bikes being checked out?¶
Refine into specific hypotheses:
- More during the weekend than on the weekdays?
- More during rush hour?
- More during the summer than the fall?
In [24]:
# Sometimes the feature you want to explore doesn’t exist in the data, and must be engineered!
# to find the time of the day we will use the start_date column and extrat the hours.
# we use list comprehension
# we will be doing a lot of those
check_out_hours = hubway_data['start_date'].apply(lambda s: int(s[-8:-6]))
In [25]:
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
check_out_counts = np.unique(check_out_hours, return_counts=True)
ax.bar(check_out_counts[0], check_out_counts[1], align='center', width=0.4, alpha=0.6)
ax.set_xlim([-1, 24])
ax.set_xticks(range(24))
ax.set_xlabel('Hour of Day')
ax.set_ylabel('Number of Checkouts')
ax.set_title('Time of Day vs Checkouts')
plt.show()
Why? For what reasons/activities are people checking out bikes?¶
Refine into specific hypotheses:
- More bikes are used for recreation than commute?
- More bikes are used for touristic purposes?
- Bikes are use to bypass traffic?
Do we have the data to answer these questions with reasonable certainty? What data do we need to collect in order to answer these questions?
How? Questions that combine variables.¶
- How does user demographics impact the duration the bikes are being used? Or where they are being checked out?
- How does weather or traffic conditions impact bike usage?
- How do the characteristics of the station location affect the number of bikes being checked out?
How questions are about modeling relationships between different variables.
In [1]:
# Here we define the distance from a point as a python function.
# We set Boston city center long and lat to be the default value.
# you will become experts in building functions and using functions just like this
def haversine(pt, lat2=42.355589, lon2=-71.060175):
"""
Calculate the great circle distance between two points
on the earth (specified in decimal degrees)
"""
lon1 = pt[0]
lat1 = pt[1]
# convert decimal degrees to radians
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
# haversine formula
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
c = 2 * asin(sqrt(a))
r = 3956 # Radius of earth in miles
return c * r
In [27]:
# use only the checkouts that we have gps location
station_counts = np.unique(hubway_data_with_gps['strt_statn'].dropna(), return_counts=True)
counts_df = pd.DataFrame({'id':station_counts[0], 'checkouts':station_counts[1]})
counts_df = counts_df.join(station_data.set_index('id'), on='id')
counts_df.head()
In [28]:
# add to the pandas dataframe the distance using the function we defined above and using map
counts_df.loc[:, 'dist_to_center'] = list(map(haversine, counts_df[['lng', 'lat']].values))
counts_df.head()
In [29]:
# we will use sklearn to fit a linear regression model
# we will learn a lot about modeling and using sklearn
reg_line = LinearRegression()
reg_line.fit(counts_df['dist_to_center'].values.reshape((len(counts_df['dist_to_center']), 1)), counts_df['checkouts'].values)
# use the fitted model to predict
distances = np.linspace(counts_df['dist_to_center'].min(), counts_df['dist_to_center'].max(), 50)
In [30]:
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.scatter(counts_df['dist_to_center'].values, counts_df['checkouts'].values, label='data')
ax.plot(distances, reg_line.predict(distances.reshape((len(distances), 1))), color='red', label='Regression Line')
ax.set_xlabel('Distance to City Center (Miles)')
ax.set_ylabel('Number of Checkouts')
ax.set_title('Distance to City Center vs Checkouts')
ax.legend()
Notice all axis are labeled, we used legends and titles when necessary. Also notice we commented our code. ¶
In [31]:
In [32]: