Starting Up¶
You can connect to the saved database from last time if you want. Alternatively, for extra practice, you can just recreate it from the datasets provided in the .txt files. That's what I'll do.
Comments¶
You should make a copy of this notebook and call it Lecture23_Exercises.ipynb. Do all excercises in a single cell immediately after the Exercise statement.
import sqlite3
import numpy as np
import pandas as pd
import time
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
db = sqlite3.connect('L23DB_demo.sqlite')
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS candidates")
cursor.execute("DROP TABLE IF EXISTS contributors")
cursor.execute("PRAGMA foreign_keys=1")
cursor.execute('''CREATE TABLE candidates (
id INTEGER PRIMARY KEY NOT NULL,
first_name TEXT,
last_name TEXT,
middle_init TEXT,
party TEXT NOT NULL)''')
db.commit() # Commit changes to the database
cursor.execute('''CREATE TABLE contributors (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
last_name TEXT,
first_name TEXT,
middle_name TEXT,
street_1 TEXT,
street_2 TEXT,
city TEXT,
state TEXT,
zip TEXT,
amount REAL,
date DATETIME,
candidate_id INTEGER NOT NULL,
FOREIGN KEY(candidate_id) REFERENCES candidates(id))''')
db.commit()
with open ("candidates.txt") as candidates:
next(candidates) # jump over the header
for line in candidates.readlines():
cid, first_name, last_name, middle_name, party = line.strip().split('|')
vals_to_insert = (int(cid), first_name, last_name, middle_name, party)
cursor.execute('''INSERT INTO candidates
(id, first_name, last_name, middle_init, party)
VALUES (?, ?, ?, ?, ?)''', vals_to_insert)
with open ("contributors.txt") as contributors:
next(contributors)
for line in contributors.readlines():
cid, last_name, first_name, middle_name, street_1, street_2, \
city, state, zip_code, amount, date, candidate_id = line.strip().split('|')
vals_to_insert = (last_name, first_name, middle_name, street_1, street_2,
city, state, int(zip_code), amount, date, candidate_id)
cursor.execute('''INSERT INTO contributors (last_name, first_name, middle_name,
street_1, street_2, city, state, zip, amount, date, candidate_id)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', vals_to_insert)
candidate_cols = [col[1] for col in cursor.execute("PRAGMA table_info(candidates)")]
contributor_cols = [col[1] for col in cursor.execute("PRAGMA table_info(contributors)")]
def viz_tables(cols, query):
q = cursor.execute(query).fetchall()
framelist = dict()
for i, col_name in enumerate(cols):
framelist[col_name] = [col[i] for col in q]
return pd.DataFrame.from_dict(framelist)
from IPython.display import display
Recap¶
Last time, you played with a bunch of SQLite commands to query and update the tables in the database.
One thing we didn't get to was how to query the contributors table based off of a query in the candidates table. For example, suppose you want to query which contributors donated to Obama. You could use a nested SELECT statement to accomplish that.
query = '''SELECT * FROM contributors WHERE candidate_id = (SELECT id from candidates WHERE last_name = "Obama")'''
display(viz_tables(contributor_cols, query))
Joins¶
The last example involved querying data from multiple tables.
In particular, we combined columns from the two related tables (related through the FOREIGN KEY).
This leads to the idea of joining multiple tables together. SQL has a set of commands to handle different types of joins. SQLite does not support the full suite of join commands offered by SQL but you should still be able to get the main ideas from the limited command set.
We'll begin with the INNER JOIN.
INNER JOIN¶
The idea here is that you will combine the tables if the values of certain columns are the same between the two tables. In our example, we will join the two tables based on the candidate id. The result of the INNER JOIN will be a new table consisting of the columns we requested and containing the common data. Since we are joining based off of the candidate id, we will not be excluding any rows.
Example¶
Here are two tables. Table A has the form:
| nA | attr | idA |
|---|---|---|
| s1 | 23 | 0 |
| s2 | 7 | 2 |
and table B has the form:
| nB | attr | idB |
|---|---|---|
| t1 | 60 | 0 |
| t2 | 14 | 7 |
| t3 | 22 | 2 |
Table A is associated with Table B through a foreign key on the id column.
If we join the two tables by comparing the id columns and selecting the nA, nB, and attr columns then we'll get
| nA | A.attr | nB | B.attr |
|---|---|---|---|
| s1 | 23 | t1 | 60 |
| s2 | 7 | t3 | 22 |
The SQLite code to do this join would be
SELECT nA, A.attr, nB, B.attr FROM A INNER JOIN B ON B.idB = A.idA
Notice that the second row in table B is gone because the id values are not the same.
Thoughts¶
What is SQL doing with this operation? It may help to visualize this with a Venn diagram. Table A has rows with values corresponding to the idA attribute. Column B has rows with values corresponding to the idB attribute. The INNER JOIN will combine the two tables such that rows with common entries in the id attributes are included. We essentially have the following Venn diagram.
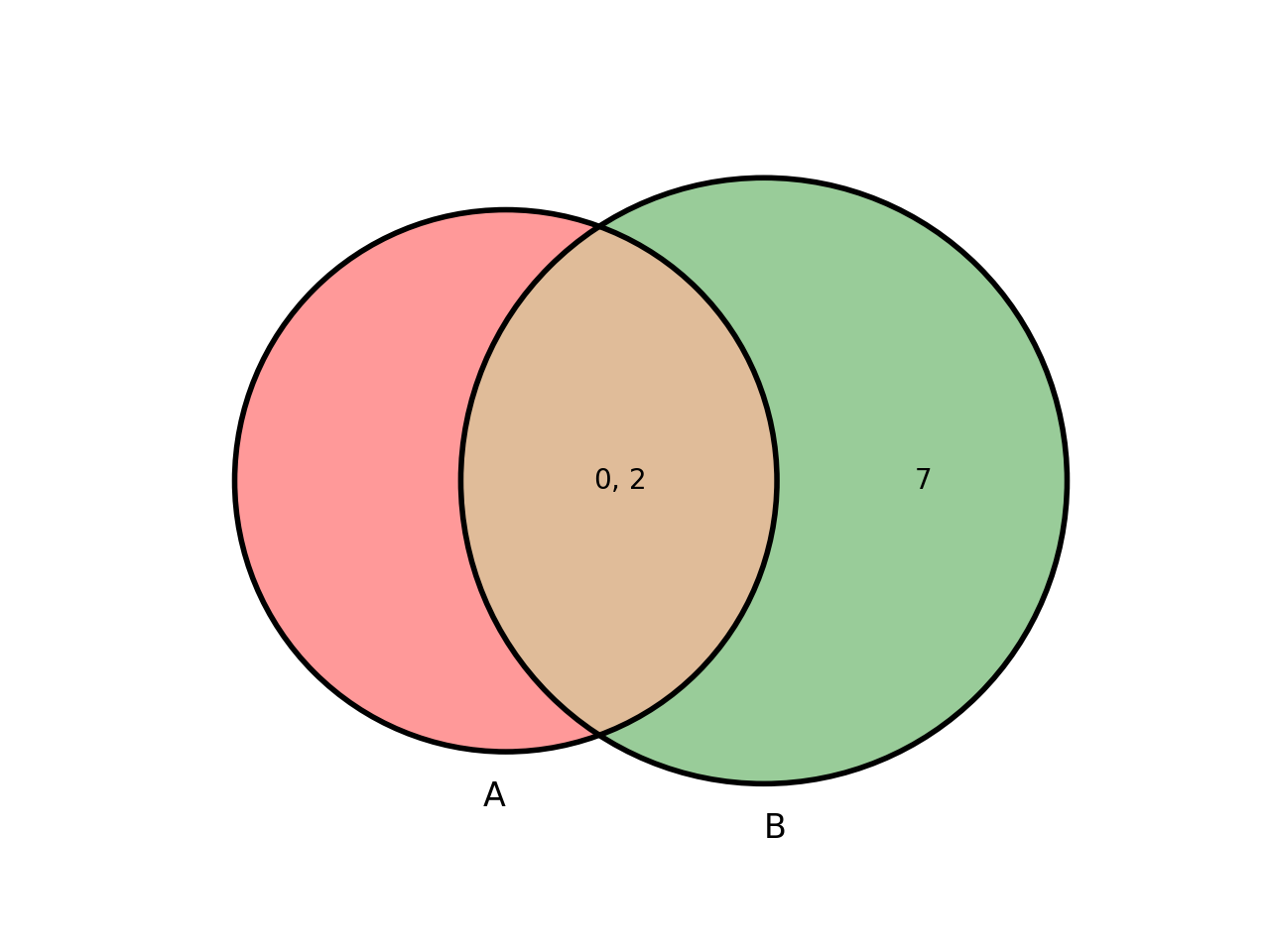
Exercises¶
- Using an
INNER JOIN, join the candidates and contributors tables by comparing thecandidate_idandcandidates_idcolumns. Display your joined table with the columnscontributors.last_name,contributors.first_name, andcandidates.last_name. - Do the same inner join as in the last part, but this time append a
WHEREclause to select a specific candidate's last name.
LEFT JOIN or LEFT OUTER JOIN¶
There are many ways to combine two tables. We just explored one possibility in which we combined the tables based upon the intersection of the two tables (the INNER JOIN).
Now we'll talk about the LEFT JOIN or LEFT OUTER JOIN.
In words, the LEFT JOIN is combining the tables based upon what is in the intersection of the two tables and what is in the "reference" table.
We can consider our toy example in two guises:
Example A¶
Let's do a LEFT JOIN of table B from table A. That is, we'd like to make a new table by putting table B into table A. In this case, we'll consider table A our "reference" table. We're comparing by the id column again. We know that these two tables share ids 0 and 2 and table A doesn't have anything else in it. The resulting table is:
| nA | A.attr | nB | B.attr |
|---|---|---|---|
| s1 | 23 | t1 | 60 |
| s2 | 7 | t3 | 22 |
That's not very exciting. It's the same result as from the INNER JOIN. We can do another example that may be more enlightening.
Example B¶
Let's do a LEFT JOIN of table A from table B. That is, we'd like to make a new table by putting table A into table B. In this case, we'll consider table B our "reference" table. Again, we use the id column from comparison. We know that these two tables share ids 0 and 2. This time, table B also contains the id 7, which is not shared by table A. The resulting table is:
| nA | A.attr | nB | B.attr |
|---|---|---|---|
| s1 | 23 | t1 | 60 |
| None | NaN | t2 | 14 |
| s2 | 7 | t3 | 22 |
Notice that SQLite filed in the missing entries for us. This is necessary for completion of the requested join.
The SQLite commands to accomplish all of this are:
SELECT nA, A.attr, nB, B.attr FROM A LEFT JOIN B ON B.idB = A.idA
and
SELECT nA, A.attr, nB, B.attr FROM B LEFT JOIN A ON A.idA = B.idB
Here is a visualization using Venn diagrams of the LEFT JOIN.
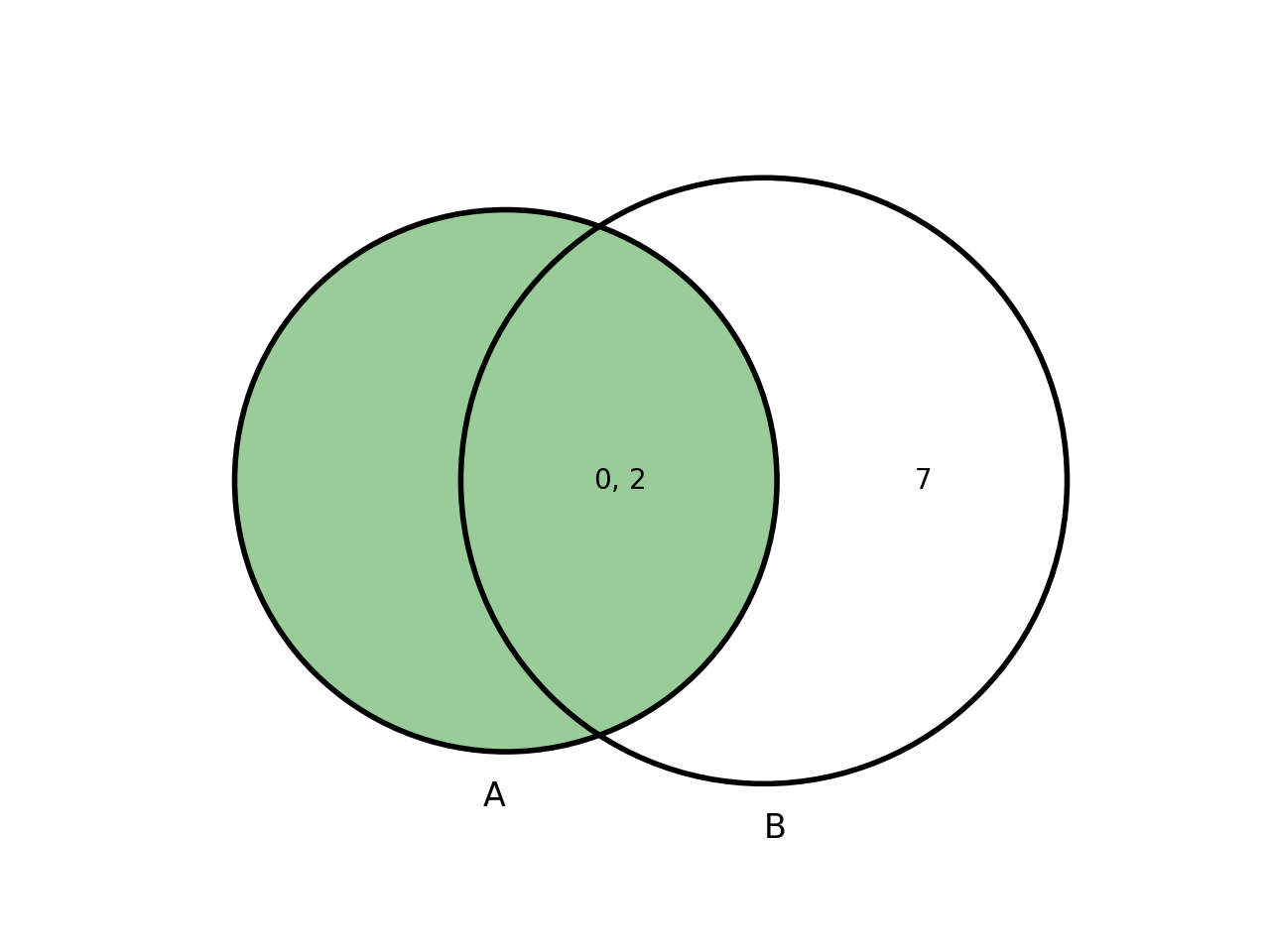
Exercises¶
Use the following two tables to do the first two exercises in this section. Table A has the form:
| nA | attr | idA |
|---|---|---|
| s1 | 23 | 0 |
| s2 | 7 | 2 |
| s3 | 15 | 3 |
| s4 | 31 | 7 |
and table B has the form:
| nB | attr | idB |
|---|---|---|
| t1 | 60 | 0 |
| t2 | 14 | 7 |
| t3 | 22 | 2 |
- Draw the table that would result from a
LEFT JOINusing table A as the reference and theidcolumns for comparison. - Draw the table that would result from a
LEFT JOINusing table B as the reference and theidcolumns for comparison. - Now back to the candidates and their contributors. Create a new table with the following form:
| average contribution | candidate last name |
|---|---|
| ... | ... |
The table should be created using the LEFT JOIN clause on the contributors table by joining the candidates table by the id column. The average contribution column should be obtained using the AVG SQL function. Finally, you should use the GROUP BY clause on the candidates last name.
pandas¶
We've been working with databases for the last few lectures and learning SQLite commands to work with and manipulate the databases. There is a Python package called pandas that provides broad support for data structures. It can be used to interact with relationsional databases through its own methods and even through SQL commands.
In the last part of this lecture, you will get to redo a bunch of the database exercises using pandas.
We won't be able to cover pandas from the ground up, but it's a well-documented library and is fairly easy to get up and running. Here's the website: pandas.
Reading a datafile into pandas¶
# Using pandas naming convention
dfcand = pd.read_csv("candidates.txt", sep="|")
dfcand
dfcontr = pd.read_csv("contributors.txt", sep="|")
dfcontr
Reading things in is quite easy with pandas.
Notice that pandas populates empty fields with NaN values.
The id column in the contributors dataset is superfluous. Let's delete it.
del dfcontr['id']
dfcontr.head()
Very nice! And we used the head method to print out the first five rows.
Creating a Table with pandas¶
We can use pandas to create tables in a database.
First, let's create a new database since we've already done a lot on our test database.
dbp = sqlite3.connect('L21_pandas_DB.sqlite')
csr = dbp.cursor()
csr.execute("DROP TABLE IF EXISTS candidates")
csr.execute("DROP TABLE IF EXISTS contributors")
csr.execute("PRAGMA foreign_keys=1")
csr.execute('''CREATE TABLE candidates (
id INTEGER PRIMARY KEY NOT NULL,
first_name TEXT,
last_name TEXT,
middle_name TEXT,
party TEXT NOT NULL)''')
dbp.commit() # Commit changes to the database
csr.execute('''CREATE TABLE contributors (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
last_name TEXT,
first_name TEXT,
middle_name TEXT,
street_1 TEXT,
street_2 TEXT,
city TEXT,
state TEXT,
zip TEXT,
amount REAL,
date DATETIME,
candidate_id INTEGER NOT NULL,
FOREIGN KEY(candidate_id) REFERENCES candidates(id))''')
dbp.commit()
Last time, we opened the data files with Python and then manually used SQLite commands to populate the individual tables. We can use pandas instead like so.
dfcand.to_sql("candidates", dbp, if_exists="append", index=False)
How big is our table?
dfcand.shape
We can visualize the data in our pandas-populated table. No surprises here except that pandas did everything for us.
query = '''SELECT * FROM candidates'''
csr.execute(query).fetchall()
Querying a table with pandas¶
One Way¶
dfcand.query("first_name=='Mike' & party=='D'")
Another Way¶
dfcand[(dfcand.first_name=="Mike") & (dfcand.party=="D")]
More Queries¶
dfcand[dfcand.middle_name.notnull()]
dfcand[dfcand.first_name.isin(['Mike', 'Hillary'])]
Exercises¶
- Use
pandasto populate the contributors table. - Query the contributors tables with the following:
- List entries where the state is "VA" and the amount is less than $\$400.00$.
- List entries where the state is "NULL".
- List entries for the states of Texas and Pennsylvania.
- List entries where the amount contributed is between $\$10.00$ and $\$50.00$.
Sorting¶
dfcand.sort_values(by='party')
dfcand.sort_values(by='party', ascending=False)
Selecting Columns¶
dfcand[['last_name', 'party']]
dfcand[['last_name', 'party']].count()
dfcand[['first_name']].drop_duplicates()
dfcand[['first_name']].drop_duplicates().count()
Exercises¶
- Sort the contributors table by
amountand order in descending order. - Select the
first_nameandamountcolumns. - Select the
last_nameandfirst_namecolumns and drop duplicates. - Count how many there are after the duplicates have been dropped.
Altering Tables¶
Creating a new column is quite easy with pandas.
dfcand['name'] = dfcand['last_name'] + ", " + dfcand['first_name']
dfcand
We can change an existing field as well.
dfcand.loc[dfcand.first_name == "Mike", "name"]
dfcand.loc[dfcand.first_name == "Mike", "name"] = "Mikey"
dfcand.query("first_name == 'Mike'")
You may recall that SQLite doesn't have the functionality to drop a column. It's a one-liner with pandas.
del dfcand['name']
dfcand
Exercises¶
- Create a name column for the contributors table with field entries of the form "last name, first name"
- For contributors from the state of "PA", change the name to "X".
- Delete the newly created name column.
Aggregation¶
We'd like to get information about the tables such as the maximum amount contributed to the candidates. Here are a bunch of ways to describe the tables.
dfcand.describe()
It's not very interesting with the candidates table because the candidates table only has one numeric column.
Exercise¶
Use the describe() method on the contributors table.
I'll use the contributors table to do some demos now.
dfcontr.amount.max()
dfcontr[dfcontr.amount==dfcontr.amount.max()]
dfcontr.groupby("state").sum()
dfcontr.groupby("state")["amount"].sum()
dfcontr.state.unique()
There is also a version of the LIMIT clause. It's very intuitive with pandas.
dfcand[0:3]
The usual Python slicing works just fine!
Joins with pandas¶
pandas has some some documentation on joins: Merge, join, and concatenate. If you want some more reinforcement on the concepts from earlier regarding JOIN, then the pandas documentation may be a good place to get it.
You may also be interested in a comparison with SQL.
To do joins with pandas, we use the merge command.
Here's an example of an explicit inner join:
cols_wanted = ['last_name_x', 'first_name_x', 'candidate_id', 'id', 'last_name_y']
dfcontr.merge(dfcand, left_on="candidate_id", right_on="id")[cols_wanted]
Somewhat organized example¶
dfcontr.merge(dfcand, left_on="candidate_id", right_on="id")[cols_wanted].groupby('last_name_y').describe()
Other Joins with pandas¶
We didn't cover all possible joins because SQLite can only handle the few that we did discuss. As mentioned, there are workarounds for some things in SQLite, but not evertyhing. Fortunately, pandas can handle pretty much everything. Here are a few joins that pandas can handle:
LEFT OUTER(already discussed)RIGHT OUTER- Think of the "opposite" of aLEFT OUTERjoin (shade the intersection and right set in the Venn diagram).FULL OUTER- Combine everything from both tables (shade the entire Venn diagram)
Left Outer Join with pandas¶
dfcontr.merge(dfcand, left_on="candidate_id", right_on="id", how="left")[cols_wanted]
Right Outer Join with pandas¶
dfcontr.merge(dfcand, left_on="candidate_id", right_on="id", how="right")[cols_wanted]
Full Outer Join with pandas¶
dfcontr.merge(dfcand, left_on="candidate_id", right_on="id", how="outer")[cols_wanted]