Key Word(s): ??
 CS109B Data Science 2: Advanced Topics
in Data Science
CS109B Data Science 2: Advanced Topics
in Data Science
Lecture 8 - Clustering with Python¶
Harvard University
Spring 2021
Instructors: Pavlos Protopapas, Mark Glickman, and Chris Tanner
Lab Instructor: Eleni Kaxiras
Content: Eleni Kaxiras, Chris Tanner, and Will Claybaugh
## RUN THIS CELL TO PROPERLY HIGHLIGHT THE EXERCISES
import requests
from IPython.core.display import HTML
styles = requests.get("https://raw.githubusercontent.com/Harvard-IACS/2019-CS109B/master/content/styles/cs109.css").text
HTML(styles)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
from sklearn.datasets import make_classification
from sklearn.datasets import make_blobs
from sklearn.datasets import make_gaussian_quantiles
%matplotlib inline
Learning Objectives¶
- Review what PCA is and know the differences between PCA and clustering,
- Understand the common distance metrics (e.g., Euclidean, Manhattan, Hamming).
- Understand how different clustering algorithms work (e.g., k-means, Hierarchical, DBSCAN).
- Quantitatively describe the quality clusters' fit, according to different metrics.
Table of Contents¶
Unsupervised Learning and Classification¶
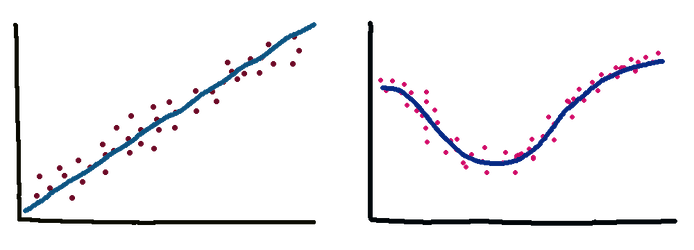
1. PCA Refresher¶

image source: [1]

image source: [1]
Sklearn's sklearn.decomposition.PCA uses the LAPACK library written in Fortran 90 (based
on the LINPACK library from the 70s) which provides routines for solving systems of simultaneous
linear equations, least-squares solutions of linear systems of equations.
How to use the sklearn PCA package:¶
a. Instantiate a new PCA object:¶
pca_transformer = PCA()
b. Fit some data (learns the transformation based on this data):¶
fitted_pca = pca_transformer.fit(data_frame)
c. Transform the data to the reduced dimensions:¶
pca_df = fitted_pca.transform(data_frame)
Using two distinct steps (i.e., (b) and (c)) to fit and transform our data allows one the flexibility
to transform any dataset according to our learned fit(). Alternatively, if you know you
only want to transform a single dataset, you can combine (b) and (c) into one step:
Fit and transform:¶
pca_df = pca_transformer.fit_transform(pca_df)
Note: We fit on the training set and transform both training and test set.
Example: Playing with synthetic data¶
Sklearn has some wonderful methods for generating
synthetic datasets. They can be quite useful for testing clustering for classification purposes.
plt.title("my synthetic data",
fontsize='medium')
X1, Y1 = make_classification(n_features=2, n_redundant=0, n_informative=1,
n_clusters_per_class=1, n_classes=1)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1,
s=25, edgecolor='k');
class_df = pd.DataFrame(X1,Y1)
plt.axis('equal');

pca_transformer = PCA(n_components=2)
fitted_pca = pca_transformer.fit(class_df)
pca_df = pd.DataFrame(fitted_pca.transform(class_df))
pca_df.head()
fitted_pca.explained_variance_ratio_
print(fitted_pca.components_), fitted_pca.mean_
For more read: "Importance of feature scaling"
Sklearn'sStandardScaler
2 - Distance Metrics¶
The Euclidean norm (or length) of a vector $\textbf{v}=[v_1,v_2,..,v_n]^T$ in $\mathbb{R}^n$ is the nonnegative scalar \begin{aligned} \lVert \textbf{v} \rVert = \sqrt{\textbf{v}\cdot \textbf{v}} = \sqrt {{ v_1}^2+{v_2}^2+\cdots+{v_n}^2} \end{aligned}
The Manhattan norm of the same vector is the nonnegative scalar \begin{aligned} \lVert \textbf{v} \rVert = \lvert \textbf{v} \rvert = \lvert v_1 \rvert + \lvert v_2 \rvert + \cdots + \lvert v_n \rvert \end{aligned}
The distance between two vectors $\textbf{v}$ and $\textbf{u}$ is defined by $d(\textbf{v}, \textbf{u}) = \lVert \textbf{v} - \textbf{u} \rVert$
Let's practice on the diagram below; we are concerned with measuring the distance between two points, $\textbf{p}=(p_1,p_2)$ and $\textbf{q}=(q_1,q_2)$.
 (edited from Wikipedia.org)
(edited from Wikipedia.org)
Euclidean distance:¶
The Euclidean distance measures the shortest path between the two points, navigating through all dimensions:
$d(\textbf{p}, \textbf{q}) = \lVert \textbf{p} - \textbf{q} \rVert = \sqrt{{(p_1-q_1)}^2+{(p_2-q_2)}^2}$
For vectors in $\mathbb{R}^n$:
$d(\textbf{p}, \textbf{q}) = \lVert \textbf{p} - \textbf{q} \rVert = \sqrt{{(p_1-q_1)}^2+{(p_2-q_2)}^2+\cdots +{(p_n-q_n)}^2}$
Manhattan distance:¶
The Manhattan distance measures the cumulative difference between the two points, across all dimensions.
$d_1(\textbf{p}, \textbf{q}) = \lVert \textbf{p} - \textbf{q} \rVert_1 = \sum_{i=1}^{n} \mid p_i-q_1 \mid$
Cosine distance (extra)¶
$\cos{\theta} = \frac{\textbf{q}\textbf{q}}{\lVert \textbf{p}\rVert \lVert\textbf{q} \rVert} $
from sklearn.feature_extraction.text import CountVectorizer
from scipy.spatial import distance
count_vect = CountVectorizer()
sent0= "Biden is here"
sent1= "President is coming here"
corpus = [sent0,sent1]
sentences = count_vect.fit_transform(corpus)
v1 = sentences.toarray()[0]
v2 = sentences.toarray()[1]
print(f'v1 = {v1}, \nv2 = {v2}')
# pretty print
df = pd.DataFrame(sentences.toarray(), \
columns=count_vect.get_feature_names(),index=['Sentence 0','Sentence 1'])
print(f'distance = {distance.cosine(v1, v2)}')
df
Note: Normally cosine value=0 means that the two vectors are orthogonal to each other. scipy implements cosine as 1-cosine, so cosine=0 means no connection and cosine=1 means orthogonal. Cosine metric is used in Collaborative Filtering (Recommender systems for movies). More on cosine distance on the second part of the class.
Hamming Distance (extra):¶
If our two elements of comparison can be represented a sequence of discrete items, it can be useful to measure how many of their elements differ.
For example:
MahmoudandMahmooddiffer by just 1 character and thus have a hamming distance of 1.10101and01101have a hamming distance of 2.MaryandBarryhave a hamming distance of 3 (m->b, y->r, null->y).
Note: the last example may seem sub-optimal, as we could transform Mary to Barry by just 2 operations (substituting the M with a B, then adding an 'r'). So, their so-called edit distance is smaller than their Hamming distance. The very related Levenshtein distance here can handle this, and thus tends to be more appropriate for Strings.
3 - Clustering Algorithms¶

We will now walk through three clustering algorithms, first discussing them at a high-level, then showing how to implement them with Python libraries. Let's first load and scale our data, so that particular dimensions don't naturally dominate in their contributions in the distant calculations:
multishapes = pd.read_csv("data/multishapes.csv")# loads x,y columns of a dataset
ms_df = multishapes[['x','y']]
ms_df.plot.scatter(x='x',y='y',c='Blue',\
title="Multishapes data",\
figsize=(5.5,4.2))
plt.show()
ms_df.head()

# displays our summary statistics of our data
ms_df.describe()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler = scaler.fit(ms_df)
print(scaler.mean_)
scaled_df = scaler.transform(ms_df)
###### if I had a test set I would transform here:
# test_scaled_df = scaler.transform(test_df)
##################################################
scaled_df = pd.DataFrame(scaled_df, \
index=multishapes['shape'], columns = ms_df.columns)
scaled_df.describe()
Very important reminder!!¶
If you have a training and a test set, always .fit() your scaler only to the training set, and then.transform() both sets.
Let's plot this data with and without scaling¶
# plot our data
msplot = ms_df.plot.scatter(x='x',y='y',c='Black',\
title="Multishapes data (no scaling)",\
figsize=(5.5,4.2))
msplot.set_xlabel("X")
msplot.set_ylabel("Y")
plt.show()

# plots our data
msplot = scaled_df.plot.scatter(x='x',y='y',c='Black',\
title="Multishapes data (w/ scaling)",\
figsize=(5.5,4.2))
msplot.set_xlabel("X")
msplot.set_ylabel("Y")
plt.show()

from sklearn.cluster import KMeans
ms_kmeans = KMeans(n_clusters=2, init='random', n_init=3, random_state=109).fit(scaled_df)
That's it! Just 1 line of code!
Now that we've run k-Means, we can look at various attributes of our clusters. Full documenation is here.
display(ms_kmeans.cluster_centers_)
display(ms_kmeans.labels_[0:10])
Plotting¶
Take note of matplotlib's c= argument to color items in the plot, along with our stacking two different plotting functions in the same plot.
plt.figure(figsize=(10,10))
plt.scatter(scaled_df['x'],scaled_df['y'], c=ms_kmeans.labels_);
plt.scatter(ms_kmeans.cluster_centers_[:,0],ms_kmeans.cluster_centers_[:,1], c='r', marker='h', s=100);

Lessons:¶
- Initializations matter; run multiple times
- k-Means can struggle with clusters that are close together; they can get lumped into one
- There's no notion of 'not part of any cluster' or 'part of two clusters' (see Gaussian Mixture Models for this).
- Visualization here
Quality of Clusters: Inertia¶
Inertia measures the total squared distance from points to their cluster's centroid. We obviously want this distance to be relatively small. If we increase the number of clusters, it will naturally make the average distance smaller. If every point has its own cluster, then our distance would be 0. That's obviously not an ideal way to cluster. One way to determine a reasonable number of clusters to simply try many different clusterings as we vary k, and each time, measure the overall inertia.
wss = []
for i in range(1,11):
fitx = KMeans(n_clusters=i, init='random', n_init=5, random_state=109).fit(scaled_df)
wss.append(fitx.inertia_)
plt.figure(figsize=(11,8.5))
plt.plot(range(1,11), wss, 'bx-')
plt.xlabel('Number of clusters $k$')
plt.ylabel('Inertia')
plt.title('The Elbow Method showing the optimal $k$')
plt.show()

Look for the place(s) where distance stops decreasing as much (i.e., the 'elbow' of the curve). It seems that 4 would be a good number of clusters, as a higher k yields diminishing returns.
Quality of Clusters: Silhouette¶
Let's say we have a data point $i$, and the cluster it belongs to is referred to as $C(i)$. One way to measure the quality of a cluster $C(i)$ is to measure how close its data points are to each other (within-cluster) compared to nearby, other clusters $C(j)$. This is what Silhouette Scores provide for us. The range is [-1,1]; 0 indicates a point on the decision boundary (equal average closeness to points intra-cluster and out-of-cluster), and negative values mean that datum might be better in a different cluster.
Specifically, let $a(i)$ denote the average distance data point $i$ is to the other points in the same cluster:
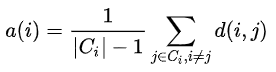
Similarly, we can also compute the average distance that data point $i$ is to all other clusters. The cluster that yields the minimum distance is denoted by $b(i)$:
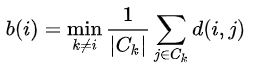
Hopefully our data point $i$ is much closer, on average, to points within its own cluster (i.e., $a(i)$ than it is to its closest neighboring cluster $b(i)$). The silhouette score quantifies this as $s(i)$:
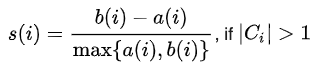
NOTE: If data point $i$ belongs to its own cluster (no other points), then the silhouette score is set to 0 (otherwise, $a(i)$ would be undefined).
The silhouette score plotted below is the overall average across all points in our dataset.
The silhouette_score() function is available in sklearn. We can manually loop over values of K (for applying k-Means algorithm), then plot its silhouette score.
from sklearn.metrics import silhouette_score
scores = [0]
for i in range(2,11):
fitx = KMeans(n_clusters=i, init='random', n_init=5, random_state=109).fit(scaled_df)
score = silhouette_score(scaled_df, fitx.labels_)
scores.append(score)
plt.figure(figsize=(11,8.5))
plt.plot(range(1,11), np.array(scores), 'bx-')
plt.xlabel('Number of clusters $k$')
plt.ylabel('Average Silhouette')
plt.title('The Elbow Method showing the optimal $k$')
plt.show()

Visualizing all Silhoutte scores for a particular clustering¶
Below, we borrow from an sklearn example. The second plot may be overkill.
- The second plot is just the scaled data. It is not a PCA plot
- If you only need the raw silhouette scores, use the
silhouette_samples()function
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.cm as cm
#modified code from http://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_silhouette_analysis.html
def silplot(X, clusterer, pointlabels=None):
cluster_labels = clusterer.labels_
n_clusters = clusterer.n_clusters
# Create a subplot with 1 row and 2 columns
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(11,8.5)
# The 1st subplot is the silhouette plot
# The silhouette coefficient can range from -1, 1 but in this example all
# lie within [-0.1, 1]
ax1.set_xlim([-0.1, 1])
# The (n_clusters+1)*10 is for inserting blank space between silhouette
# plots of individual clusters, to demarcate them clearly.
ax1.set_ylim([0, len(X) + (n_clusters + 1) * 10])
# The silhouette_score gives the average value for all the samples.
# This gives a perspective into the density and separation of the formed
# clusters
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters = ", n_clusters,
", the average silhouette_score is ", silhouette_avg,".",sep="")
# Compute the silhouette scores for each sample
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(0,n_clusters+1):
# Aggregate the silhouette scores for samples belonging to
# cluster i, and sort them
ith_cluster_silhouette_values = \
sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
# Label the silhouette plots with their cluster numbers at the middle
ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
# Compute the new y_lower for next plot
y_lower = y_upper + 10 # 10 for the 0 samples
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
# The vertical line for average silhouette score of all the values
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([]) # Clear the yaxis labels / ticks
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
# 2nd Plot showing the actual clusters formed
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1], marker='.', s=200, lw=0, alpha=0.7,
c=colors, edgecolor='k')
xs = X[:, 0]
ys = X[:, 1]
if pointlabels is not None:
for i in range(len(xs)):
plt.text(xs[i],ys[i],pointlabels[i])
# Labeling the clusters
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='o',
c="white", alpha=1, s=200, edgecolor='k')
for i, c in enumerate(centers):
ax2.scatter(c[0], c[1], marker='$%d$' % int(i), alpha=1,
s=50, edgecolor='k')
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
# run k-means with 3 clusters
ms_kmeans = KMeans(n_clusters=4, init='random', n_init=3, random_state=109).fit(scaled_df)
# plot a fancy silhouette plot
silplot(scaled_df.values, ms_kmeans)

Using the silhouette scores' optimal number of clusters (per the elbow plot above):
- Fit a new k-Means model with that many clusters
- Plot the clusters like we originally did with k-means
- Plot the silhouette scores just like the above cells
- Which seems like a better clustering (i.e., 3 clusters or the number returned by the elbow plot above)?
Quality of Clusters: Gap Statistic¶
The gap statistic compares within-cluster distances (such as in silhouette), but instead of comparing against the second-best existing cluster for that point, it compares our clustering's overall average to the average we'd see if the data were generated at random (we'd expect randomly generated data to not necessarily have any inherit patterns that can be easily clustered).
In essence, the within-cluster distances (in the elbow plot) will go down just becuse we have more clusters. We additionally calculate how much they'd go down on non-clustered data with the same spread as our data and subtract that trend out to produce the plot below.
The original paper is : "Estimating the number of clusters in a data set via the gap statistic" (Tibshirani et al.).
As suggested in the paper, we would choose the value of $\hat{k}$ (number of clusters) such that
$\hat{k}$ = smallest $k$ such that Gap($k$) $\geq$ Gap($k+1$) - $s_{k+1}$.
We compare the actual Gap value of the k point to the lower bar of the Gap value of the k+1 point. The following graph should make it clearer. The plot is from the original paper (Fig. 2) (dashed lines are mine)
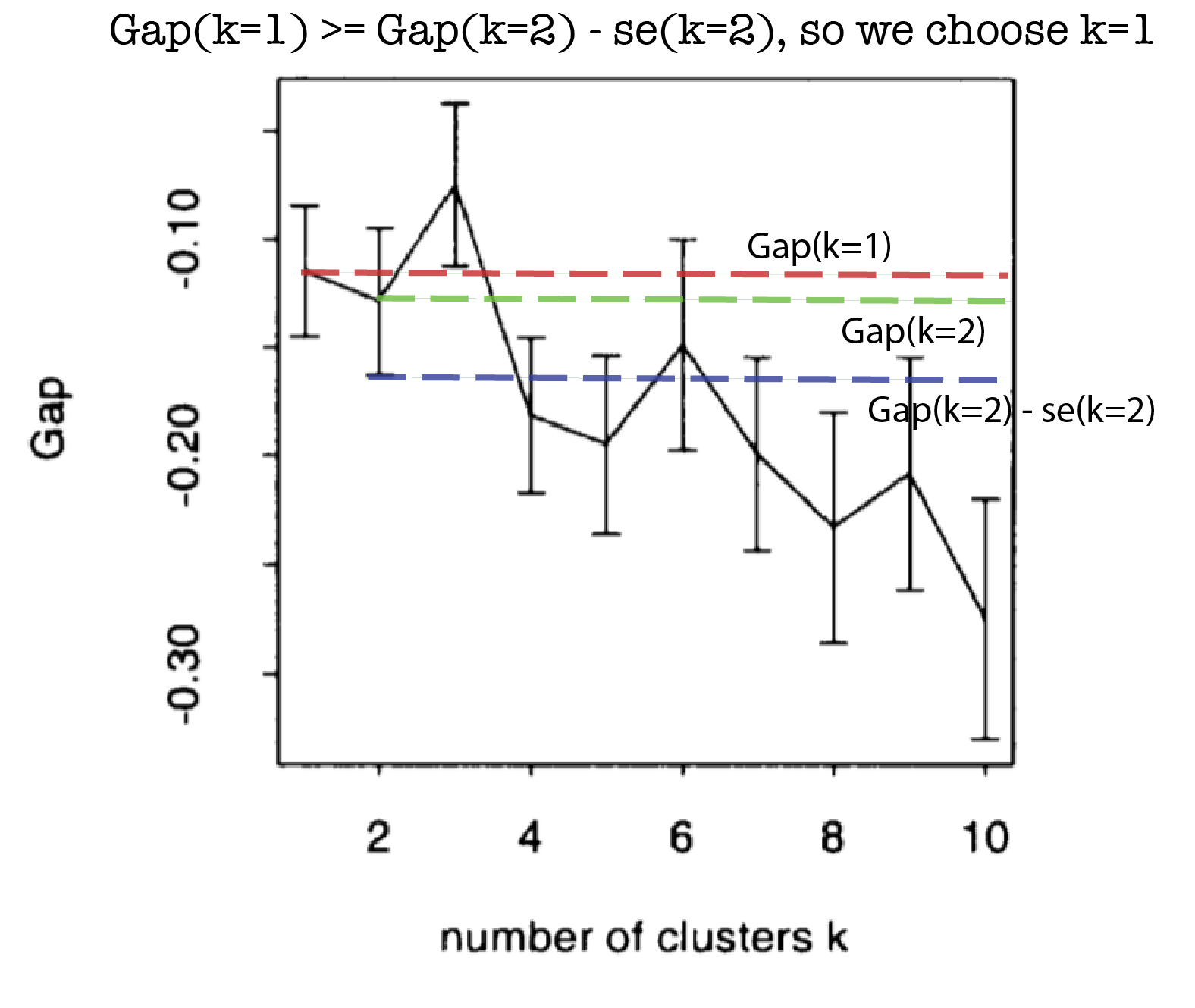
We could argue that we should have chosen the largest value (k =3) instead of the first value that satisfies the Gap statistic equation (k=1 in this case). If you're able to compute for a range of k, then you can choose the maximum. For example, in the graph above, since we're computing over k=1,..,10, we could choose k=3. The original paper although it suggests that we look at the whole range, chooses k=1 in the case above; if you see the raw data plotted (Fig. 2 in the paper) you will also notice that there is really not much structure for cluster subdivision but we should always investigate the whole plot. Also, it's very computationally intensive to compute the Gap statistic.
Additionally, you can use domain knowledge or whatever information you have about the data to choose k.
The gap statistic is implemented by Miles Granger in the gap_statistic Python library. The library also implements the Gap$^*$ statistic described in "A comparison of Gap statistic definitions with and with-out logarithm function" (Mohajer, M., Englmeier, K. H., & Schmid, V. J., 2011) which is less conservative but tends to perform suboptimally when clusters overlap.
from gap_statistic import OptimalK
from sklearn.datasets.samples_generator import make_blobs
from sklearn.datasets import make_classification
import warnings
warnings.filterwarnings('ignore')
Playing with synthetic data¶
Sklearn has some wonderful methods for generative synthetic datasets. They can be quite useful for testing clustering for classification purposes.
plt.title("Three blobs", fontsize='small')
X1, Y1 = make_blobs(n_features=2, centers=4) # centers is number of classes
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1,
s=25, edgecolor='k');
blob_df = pd.DataFrame(X1,Y1)
plt.axis('equal');
blob_df.head()

gs_obj = OptimalK(n_jobs=1, n_iter= 10)
n_clusters = gs_obj(X1, n_refs=50, cluster_array=np.arange(1, 15))
print('Optimal number of clusters: ', n_clusters)
ms_kmeans = KMeans(n_clusters=n_clusters, init='random',\
n_init=3, random_state=109).fit(X1)
plt.figure(figsize=(5,5))
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1,
s=25, edgecolor='k');
plt.scatter(ms_kmeans.cluster_centers_[:,0],\
ms_kmeans.cluster_centers_[:,1], c='r', marker='h', s=200);
plt.axis('equal');

gs_obj.plot_results()




# show GAP and GAP* statistics
gs_obj.gap_df .iloc[:,:3]
If we wish to add error bars to help us decide how many clusters to use, the following code displays such:
def display_gapstat_with_errbars(gap_df):
gaps = gap_df["gap_value"].values
diffs = gap_df["diff"]
err_bars = np.zeros(len(gap_df))
err_bars[1:] = diffs[:-1] - gaps[:-1] + gaps[1:]
plt.scatter(gap_df["n_clusters"], gap_df["gap_value"])
plt.errorbar(gap_df["n_clusters"], gap_df["gap_value"], yerr=err_bars, capsize=6)
plt.xlabel("Number of Clusters")
plt.ylabel("Gap Statistic")
plt.show()
display_gapstat_with_errbars(gs_obj.gap_df)

For more information about the gap_stat package, please see the full documentation here.
3b. Agglomerative Clustering¶
Code (via scipy):¶
There are many different cluster-merging criteria, one of which is Ward's criteria. Ward's optimizes having the lowest total within-cluster distances, so it merges the two clusters that will harm this objective least.
scipy's agglomerative clustering function implements Ward's method.
import scipy.cluster.hierarchy as hac
from scipy.spatial.distance import pdist
plt.figure(figsize=(11,8.5))
dist_mat = pdist(scaled_df, metric="euclidean")
ward_data = hac.ward(dist_mat)
hac.dendrogram(ward_data);
plt.show()

Lessons:¶
- It's expensive: O(n^3) time complexity and O(n^2) space complexity.
- Many choices for linkage criteria
- Every node gets clustered (no child left behind)
3c. DBSCAN Clustering¶
DBSCAN uses an intuitive notion of denseness to define clusters, rather than defining clusters by a central point as in k-means.
Code (via sklearn):¶
DBscan is implemented in good 'ol sklearn, but there aren't great automated tools for searching for the optimal epsilon parameter. For full documentation, please visit this page
from sklearn.cluster import DBSCAN
plt.figure(figsize=(11,8.5))
fitted_dbscan = DBSCAN(eps=0.2).fit(scaled_df)
plt.scatter(scaled_df['x'],scaled_df['y'], c=fitted_dbscan.labels_);

Note: the dark purple dots are not clustered with anything else. They are lone singletons. You can validate such by setting epsilon to a very small value, and increase the min_samples to a high value. Under these conditions, nothing would cluster, and yet all dots become dark purple.
Instead of just empirically observing how the epsilon value affects the clustering (which would be very costly for large, high-dimensional data), we can also inspect how far each data point is to its $N^{th}$ closest neighbor:
from sklearn.neighbors import NearestNeighbors
# x-axis is each individual data point, numbered by an artificial index
# y-axis is the distance to its 2nd closest neighbor
def plot_epsilon(df, min_samples):
fitted_neigbors = NearestNeighbors(n_neighbors=min_samples).fit(df)
distances, indices = fitted_neigbors.kneighbors(df)
dist_to_nth_nearest_neighbor = distances[:,-1]
plt.plot(np.sort(dist_to_nth_nearest_neighbor))
plt.xlabel("Index\n(sorted by increasing distances)")
plt.ylabel("{}-NN Distance (epsilon)".format(min_samples-1))
plt.tick_params(right=True, labelright=True)
plot_epsilon(scaled_df, 3)

Lessons:¶
- Can cluster non-linear relationships very well; potential for more natural, arbritrarily shaped groupings
- Does not require specifying the # of clusters (i.e., k); the algorithm determines such
- Robust to outliers
- Very sensitive to the parameters (requires strong knowledge of the data)
- Doesn't guarantee that every (or ANY) item will be clustered
When should we prefer one type of clustering over another? Should we always just try all of them? Imagine you work at Spotify and you want to create personalized playlists for each person. One could imagine a dataset exists whereby each row is a particular song, and the columns are features (e.g., tempo (BPM), average vocal frequency, amount of bass, sentiment of lyrics, duration in seconds, etc). Let's use clustering to group one's catalog of favorite music, which will serve as disjoint starting points for suggesting future songs. Specifically, imagine that you've 'liked' 500 songs on Spotify so far, and your recommendation algorithm needs to cluster those 500 songs. Would you first experiment with k-Means, Agglomerative, or DBScan? Why?