 CS-109B Advanced Data Science
CS-109B Advanced Data Science
Lab 9: Recurrent Neural Networks (Part II)¶
Harvard University
Fall 2020
Instructors: Mark Glickman, Pavlos Protopapas, and Chris Tanner
Lab Instructors: Chris Tanner and Eleni Angelaki Kaxiras
Content: Srivatsan Srinivasan, Pavlos Protopapas, Chris Tanner
# RUN THIS CELL TO PROPERLY HIGHLIGHT THE EXERCISES
import requests
from IPython.core.display import HTML
styles = requests.get("https://raw.githubusercontent.com/Harvard-IACS/2019-CS109B/master/content/styles/cs109.css").text
HTML(styles)
Learning Goals¶
In this lab, we will continue where we left off in Lab 8. By the end of this lab, you should:
- feel comfortable modelling sequences in
kerasvia RNNs and its variants (GRUs, LSTMs) - have a good undertanding on how sequences -- any data that has some temporal semantics (e.g., time series, natural language, images etc.) -- fit into and benefit from a recurrent architecture
- ask any other NLP questions that you're curious about. This lab is the closest one we'll ever have to being an Office Hour.
Seq2Seq Model: 231+432 = 665.... It's not ? Let's ask our LSTM¶
In this exercise, we are going to teach addition to our model. Given two numbers (<999), the model outputs their sum (<9999). The input is provided as a string '231+432' and the model will provide its output as ' 663' (Here the empty space is the padding character). We are not going to use any external dataset and are going to construct our own dataset for this exercise.
The exercise we attempt to do effectively "translates" a sequence of characters '231+432' to another sequence of characters ' 663' and hence, this class of models are called sequence-to-sequence models (aka seq2seq). Such architectures have profound applications in several real-life tasks such as machine translation, summarization, image captioning etc.
To be clear, sequence-to-sequence (aka seq2seq) models take as input a sequence of length N and return a sequence of length M, where N and M may or may not differ, and every single observation/input may be of different values, too. For example, machine translation concerns converting text from one natural language to another (e.g., translating English to French). Google Translate is an example, and their system is a seq2seq model. The input (e.g., an English sentence) can be of any length, and the output (e.g., a French sentence) may be of any length.
Background knowledge: The earliest and most simple seq2seq model works by having one RNN for the input, just like we've always done, and we refer to it as being an "encoder." The final hidden state of the encoder RNN is fed as input to another RNN that we refer to as the "decoder." The job of the decoder is to generate each token, one word at a time. This may seem really limiting, as it relies on the encoder encapsulating the entire input sequence with just 1 hidden layer. It seems unrealistic that we could encode an entire meaning of a sentence with just one hidden layer. Yet, results even in this simplistic manner can be quite impressive. In fact, these early results were compelling enough that these models immediately replaced the decades of earlier machine translation work.
from __future__ import print_function
from keras.models import Sequential
from keras import layers
from keras.layers import Dense, RepeatVector, TimeDistributed
import numpy as np
from six.moves import range
Data preprocessing and handling¶
class CharacterTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
# converts a String of characters into a one-hot embedding/vector
def encode(self, C, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(C):
x[i, self.char_indices[c]] = 1
return x
# converts a one-hot embedding/vector into a String of characters
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = x.argmax(axis=-1)
return ''.join(self.indices_char[x] for x in x)
TRAINING_SIZE = 50000
DIGITS = 3
MAXOUTPUTLEN = DIGITS + 1
MAXLEN = DIGITS + 1 + DIGITS
chars = '0123456789+ '
ctable = CharacterTable(chars)
def return_random_digit():
return np.random.choice(list('0123456789'))
# generate a new number of length `DIGITS`
def generate_number():
num_digits = np.random.randint(1, DIGITS + 1)
return int(''.join( return_random_digit()
for i in range(num_digits)))
# generate `TRAINING_SIZE` # of pairs of random numbers
def data_generate(num_examples):
questions = []
answers = []
seen = set()
print('Generating data...')
while len(questions) < TRAINING_SIZE:
a, b = generate_number(), generate_number()
# don't allow duplicates; this is good practice for training,
# as we will minimize memorizing seen examples
key = tuple(sorted((a, b)))
if key in seen:
continue
seen.add(key)
# pad the data with spaces so that the length is always MAXLEN.
q = '{}+{}'.format(a, b)
query = q + ' ' * (MAXLEN - len(q))
ans = str(a + b)
# answers can be of maximum size DIGITS + 1.
ans += ' ' * (MAXOUTPUTLEN - len(ans))
questions.append(query)
answers.append(ans)
print('Total addition questions:', len(questions))
return questions, answers
def encode_examples(questions, answers):
x = np.zeros((len(questions), MAXLEN, len(chars)), dtype=np.bool)
y = np.zeros((len(questions), DIGITS + 1, len(chars)), dtype=np.bool)
for i, sentence in enumerate(questions):
x[i] = ctable.encode(sentence, MAXLEN)
for i, sentence in enumerate(answers):
y[i] = ctable.encode(sentence, DIGITS + 1)
indices = np.arange(len(y))
np.random.shuffle(indices)
return x[indices],y[indices]
q, a = data_generate(TRAINING_SIZE)
x, y = encode_examples(q,a)
# divides our data into training and validation
split_at = len(x) - len(x) // 10
x_train, x_val, y_train, y_val = x[:split_at], x[split_at:],y[:split_at],y[split_at:]
print('Training Data shape:')
print('X : ', x_train.shape)
print('Y : ', y_train.shape)
print('Sample Question(in encoded form) : ', x_train[0], y_train[0])
print('Sample Question(in decoded form) : ', ctable.decode(x_train[0]),'Sample Output : ', ctable.decode(y_train[0]))
Let's learn two wrapper functions in Keras - TimeDistributed and RepeatVector with some dummy examples.¶
TimeDistributed is a wrapper function call that applies an input operation (e.g., NN layer) on each of the timesteps of an input data. Read the documentation here. For instance, perhaps you have a 5-dimensional input. Instead of simply outputting a single value for each of the 5 inputs, let's say that you want to emit an 8-dimensional output for each input. We can do this simply by using a TimeDistrubted layer while specifying that we want a fully-connected layer that applies itself to each of the 5 input time steps and emits 8 outputs for each. Below, we illustrate such:
# Inputs will be a tensor of size: batch_size * time_steps * input_vector_dim(to Dense)
# Output will be a tensor of size: batch_size * time_steps * output_vector_dim(i.e., 8)
model = Sequential()
# Here, Dense() converts a 5-dim input vector to a 8-dim vector.
model.add(TimeDistributed(Dense(8), input_shape=(3, 5)))
input_array = np.random.randint(10, size=(1,3,5))
print("Shape of input : ", input_array.shape)
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
print("Shape of output : ", output_array.shape)
RepeatVector repeats the vector a specified number of times. Dimension changes from batch_size number of elements to batch_size number of repetitions * number of elements.
model = Sequential()
# converts tensor from size of 1*10 to 1*6
model.add(Dense(6, input_dim=10))
print(model.output_shape)
# converts tensor from size of 1*6 to size of 1*3*6
model.add(RepeatVector(3))
print(model.output_shape)
input_array = np.random.randint(1000, size=(1, 10))
print("Shape of input : ", input_array.shape)
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
print("Shape of output : ", output_array.shape)
# note: `None` is the batch dimension
print('Input : ', input_array[0])
print('Output : ', output_array[0])
MODEL ARCHITECTURE¶
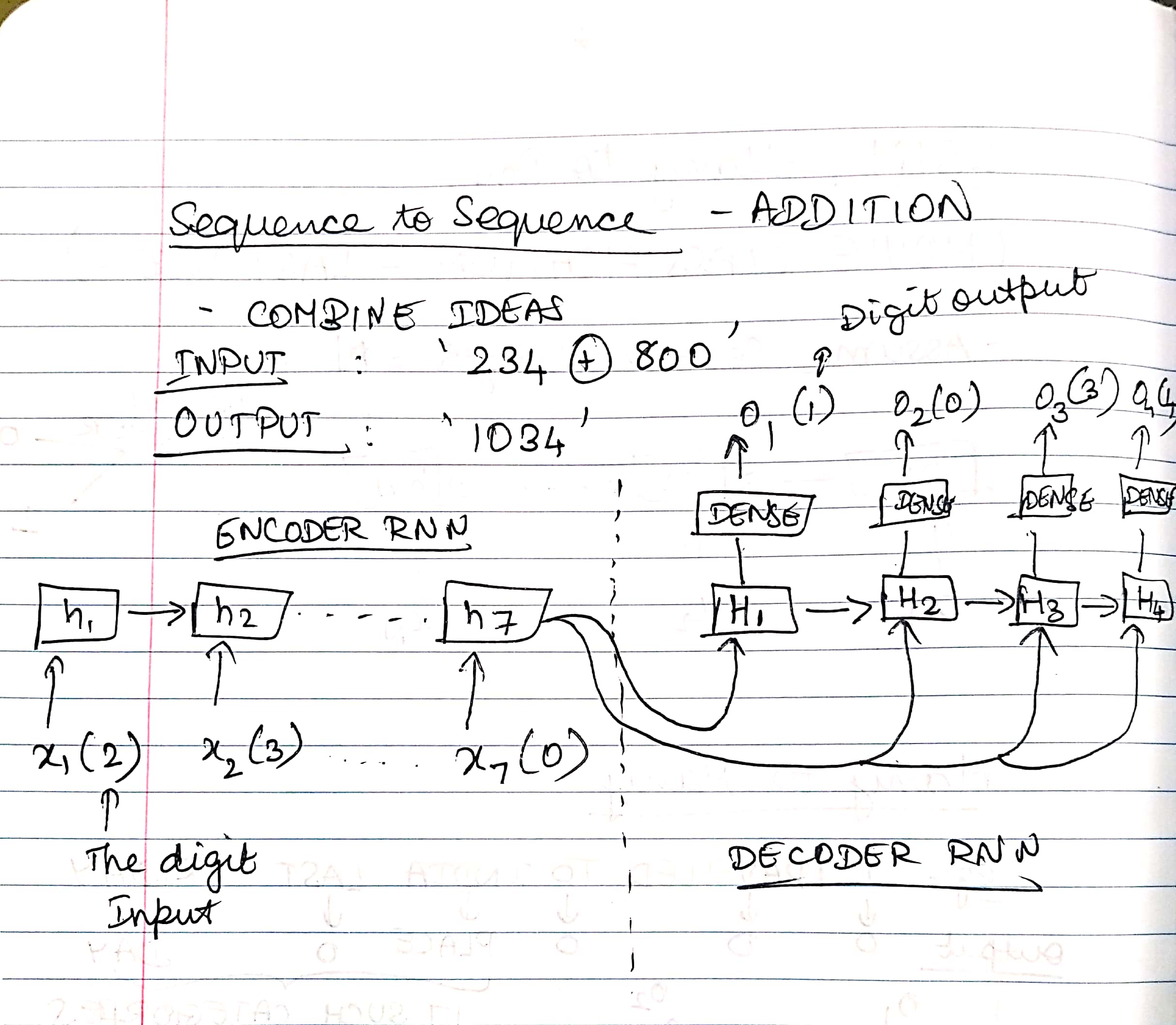
Note: Whenever you are initializing a LSTM in Keras, by the default the option return_sequences = False. This means that at the end of the step the next component will only get to see the final hidden layer's values. On the other hand, if you set return_sequences = True, the LSTM component will return the hidden layer at each time step. It means that the next component should be able to consume inputs in that form.
Think how this statement is relevant in terms of this model architecture and the TimeDistributed module we just learned.
Build an encoder and decoder both single layer 128 nodes and an appropriate dense layer as needed by the model.
# Hyperaparams
RNN = layers.LSTM
HIDDEN_SIZE = 128
BATCH_SIZE = 128
LAYERS = 1
print('Build model...')
model = Sequential()
# ENCODING
model.add(RNN(HIDDEN_SIZE, input_shape=(MAXLEN, len(chars))))
model.add(RepeatVector(MAXOUTPUTLEN))
# DECODING
for _ in range(LAYERS):
# return hidden layer at each time step
model.add(RNN(HIDDEN_SIZE, return_sequences=True))
model.add(TimeDistributed(layers.Dense(len(chars), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
Let's check how well our model trained.
for iteration in range(1, 2):
print()
model.fit(x_train, y_train,
batch_size=BATCH_SIZE,
epochs=20,
validation_data=(x_val, y_val))
# Select 10 samples from the validation set at random so
# we can visualize errors.
print('Finished iteration ', iteration)
numcorrect = 0
numtotal = 20
for i in range(numtotal):
ind = np.random.randint(0, len(x_val))
rowx, rowy = x_val[np.array([ind])], y_val[np.array([ind])]
preds = model.predict_classes(rowx, verbose=0)
q = ctable.decode(rowx[0])
correct = ctable.decode(rowy[0])
guess = ctable.decode(preds[0], calc_argmax=False)
print('Question', q, end=' ')
print('True', correct, end=' ')
print('Guess', guess, end=' ')
if guess == correct :
print('Good job')
numcorrect += 1
else:
print('Fail')
print('The model scored ', numcorrect*100/numtotal,' % in its test.')
EXERCISE¶
Try changing the hyperparams, use other RNNs, more layers, check if increasing the number of epochs is useful.
Try reversing the data from validation set and check if commutative property of addition is learned by the model.
Try printing the hidden layer with two inputs that are commutative and check if the hidden representations it learned are same or similar. Do we expect it to be true? If so, why? If not why? You can access the layer using an index with model.layers and layer.output will give the output of that layer.
Try doing addition in the RNN model the same way we do by hand. Reverse the order of digits and at each time step, input two digits get an output use the hidden layer and input next two digits and so on. (units in the first time step, tens in the second time step etc.)
Extra HW tidbits:¶
pad_sequences()¶
When working with sequences, it is usually important to ensure that our input sequences are of the same length -- especially when doing reading inputs in batches. A simple and common approach is to make our input length be that of a our longest input. All inputs that are shorter than this will be padded with a particular value of your choice. Also, if any inputs happen to be longer than our specified length (again, we typically set this to be that of our longest input), then they will be truncated to that length. Click here for the Keras documentation
Embedding layers¶
Embeddings layers, when used in Keras, must be the 1st layer of your network. They transform vectors from one space into another. Typically, this learned embedding is of a smaller size than the original. The power of this layer is that the Embeddings will be learned by the network.