 CS109B Data Science 2: Advanced Topics in Data Science
CS109B Data Science 2: Advanced Topics in Data Science
Lab 2 - Smoothers and Generalized Additive Models - Model Fitting¶
Harvard University
Spring 2020
Instructors: Mark Glickman, Pavlos Protopapas, and Chris Tanner
Lab Instructors: Chris Tanner and Eleni Kaxiras
Content: Eleni Kaxiras and Will Claybaugh
## RUN THIS CELL TO PROPERLY HIGHLIGHT THE EXERCISES
import requests
from IPython.core.display import HTML
styles = requests.get("https://raw.githubusercontent.com/Harvard-IACS/2019-CS109B/master/content/styles/cs109.css").text
HTML(styles)
import numpy as np
from scipy.interpolate import interp1d
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
Learning Goals¶
By the end of this lab, you should be able to:
- Understand how to implement GAMs with the Python package
pyGAM - Learn about the practical aspects of Splines and how to use them.
This lab corresponds to lectures 1, 2, and 3 and maps to homework 1.
Table of Contents¶
- 1 - Overview - A Top View of LMs, GLMs, and GAMs to set the stage
- 2 - A review of Linear Regression with
statsmodels. What are those weird formulas? - 3 - Splines
- 4 - Generative Additive Models with pyGAM
- 5 - Smooting Splines using pyGAM
Overview¶
Linear Models (LM), Generalized Linear Models (GLMs), Generalized Additive Models (GAMs), Splines, Natural Splines, Smoothing Splines! So many definitions. Let's try and work through an example for each of them so we can better understand them.
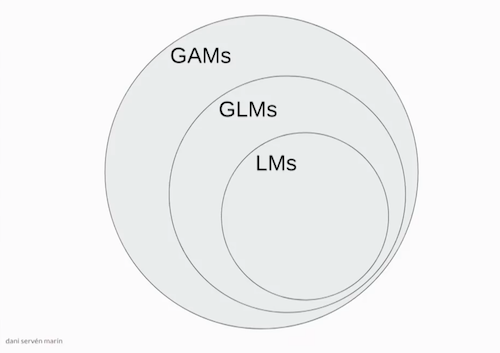 image source: Dani Servén Marín (one of the developers of pyGAM)
image source: Dani Servén Marín (one of the developers of pyGAM)
A - Linear Models¶
First we have the Linear Models which you know from 109a. These models are linear in the coefficients. Very interpretable but suffer from high bias because let's face it, few relationships in life are linear. Simple Linear Regression (defined as a model with one predictor) as well as Multiple Linear Regression (more than one predictors) are examples of LMs. Polynomial Regression extends the linear model by adding terms that are still linear for the coefficients but non-linear when it somes to the predictiors which are now raised in a power or multiplied between them.
- What does it mean for a model to be interpretable?
- Are linear regression models interpretable? Are random forests? What about Neural Networks such as FFNs and CNNs?
- Do we always want interpretability? Describe cases where we do and cases where we do not care.
B - Generalized Linear Models (GLMs)¶
Generalized Linear Models is a term coined in the early 1970s by Nelder and Wedderburn for a class of models that includes both Linear Regression and Logistic Regression. A GLM fits one coefficient per feature (predictor).
C - Generalized Additive Models (GAMs)¶
Hastie and Tidshirani coined the term Generalized Additive Models in 1986 for a class of non-linear extensions to Generalized Linear Models.
In practice we add splines and regularization via smoothing penalties to our GLMs. Decision Trees also fit in this category.
image source: Dani Servén Marín
D - Basis Functions¶
In our models we can use various types of functions as "basis".
- Monomials such as $x^2$, $x^4$ (Polynomial Regression)
- Sigmoid functions (neural networks)
- Fourier functions
- Wavelets
- Regression splines which we will look at shortly.
- Where does polynomial regression fit in all this?
Answer: GLMs include Polynomial Regression so the graphic above should really include curved lines, not just straight...
Implementation¶
1 - Linear/Polynomial Regression¶
We will use the diabetes dataset.
Variables are:
- subject: subject ID number
- age: age diagnosed with diabetes
- acidity: a measure of acidity called base deficit Response:
- y: natural log of serum C-peptide concentration
Original source is Sockett et al. (1987) mentioned in Hastie and Tibshirani's book "Generalized Additive Models".
Reading data and (some) exploring in Pandas:
diab = pd.read_csv("../data/diabetes.csv")
diab.head()
diab.dtypes
diab.describe()
Plotting with matplotlib:
ax0 = diab.plot.scatter(x='age',y='y',c='Red',title="Diabetes data") #plotting direclty from pandas!
ax0.set_xlabel("Age at Diagnosis")
ax0.set_ylabel("Log C-Peptide Concentration");

Linear/Polynomial regression with statsmodels.¶
As you remember from 109a, we have two tools for Linear Regression:
statsmodelshttps://www.statsmodels.org/stable/regression.html, andsklearnhttps://scikit-learn.org/stable/index.html
Previously, we worked from a vector of target values and a design matrix we built ourself (e.g. using sklearn's PolynomialFeatures). statsmodels allows users to fit statistical models using R-style formulas. They build the target value and design matrix for you.
# our target variable is 'Lottery', while 'Region' is a categorical predictor
df = dta.data[['Lottery', 'Literacy', 'Wealth', 'Region']]
formula='Lottery ~ Literacy + Wealth + C(Region) + Literacy * Wealth'For more on these formulas see:
import statsmodels.formula.api as sm
model1 = sm.ols('y ~ age',data=diab)
fit1_lm = model1.fit()
Let's build a dataframe to predict values on (sometimes this is just the test or validation set). Very useful for making pretty plots of the model predictions - predict for TONS of values, not just whatever's in the training set.
x_pred = np.linspace(0,16,100)
predict_df = pd.DataFrame(data={"age":x_pred})
predict_df.head()
Use get_prediction().summary_frame() to get the model's prediction (and error bars!)
prediction_output = fit1_lm.get_prediction(predict_df).summary_frame()
prediction_output.head()
Plot the model and error bars
ax1 = diab.plot.scatter(x='age',y='y',c='Red',title="Diabetes data with least-squares linear fit")
ax1.set_xlabel("Age at Diagnosis")
ax1.set_ylabel("Log C-Peptide Concentration")
ax1.plot(predict_df.age, prediction_output['mean'],color="green")
ax1.plot(predict_df.age, prediction_output['mean_ci_lower'], color="blue",linestyle="dashed")
ax1.plot(predict_df.age, prediction_output['mean_ci_upper'], color="blue",linestyle="dashed");

- Fit a 3rd degree polynomial model and
- plot the model+error bars.
You can either take
- Route1: Build a design df with a column for each of
age,age**2,age**3, or - Route2: Just edit the formula
# your answer here
# %load ../solutions/exercise1-1.py
fit2_lm = sm.ols(formula="y ~ age + np.power(age, 2) + np.power(age, 3)",data=diab).fit()
poly_predictions = fit2_lm.get_prediction(predict_df).summary_frame()
poly_predictions.head()
# %load ../solutions/exercise1-2.py
ax2 = diab.plot.scatter(x='age',y='y',c='Red',title="Diabetes data with least-squares cubic fit")
ax2.set_xlabel("Age at Diagnosis")
ax2.set_ylabel("Log C-Peptide Concentration")
ax2.plot(predict_df.age, poly_predictions['mean'],color="green")
ax2.plot(predict_df.age, poly_predictions['mean_ci_lower'], color="blue",linestyle="dashed")
ax2.plot(predict_df.age, poly_predictions['mean_ci_upper'], color="blue",linestyle="dashed");

This example was similar with the Ed exercise. Open it in Ed and let's go though it.
2 - Piecewise Polynomials a.k.a. Splines¶
Splines are a type of piecewise polynomial interpolant. A spline of degree k is a piecewise polynomial that is continuously differentiable k − 1 times.
Splines are the basis of CAD software and vector graphics including a lot of the fonts used in your computer. The name “spline” comes from a tool used by ship designers to draw smooth curves. Here is the letter $epsilon$ written with splines:
font idea inspired by David Knezevic (AM205)
If the degree is 1 then we have a Linear Spline. If it is 3 then we have a Cubic spline. It turns out that cubic splines because they have a continous 2nd derivative at the knots are very smoothly looking to the eye. We do not need higher order than that. The Cubic Splines are usually Natural Cubic Splines which means they have the added constrain of the end points' second derivative = 0.
We will use the CubicSpline and the B-Spline as well as the Linear Spline.
scipy.interpolate¶
See all the different splines that scipy.interpolate has to offer: https://docs.scipy.org/doc/scipy/reference/interpolate.html
Let's use the simplest form which is interpolate on a set of points and then find the points between them.
from scipy.interpolate import splrep, splev
from scipy.interpolate import BSpline, CubicSpline
from scipy.interpolate import interp1d
# define the range of the function
a = -1
b = 1
# define the number of knots
num_knots = 10
x = np.linspace(a,b,num_knots)
# define the function we want to approximate
y = 1/(1+25*(x**2))
# make a linear spline
linspline = interp1d(x, y)
# sample at these points to plot
xx = np.linspace(a,b,1000)
yy = 1/(1+25*(xx**2))
plt.plot(x,y,'*')
plt.plot(xx, yy, label='true function')
plt.plot(xx, linspline(xx), label='linear spline');
plt.legend();

The Linear interpolation does not look very good. Fit a Cubic Spline and plot along the Linear to compare.
# your answer here
# %load ../solutions/exercise2.py
# define the range of the function
a = -1
b = 1
# define the knots
num_knots = 10
x = np.linspace(a,b,num_knots)
# define the function we want to approximate
y = 1/(1+25*(x**2))
# make the Cubic spline
cubspline = CubicSpline(x, y)
# OR make a linear spline
linspline = interp1d(x, y)
# plot
xx = np.linspace(a,b,1000)
yy = 1/(1+25*(xx**2))
plt.plot(xx, yy, label='true function')
plt.plot(x,y,'*')
plt.plot(xx, linspline(xx), label='linear');
plt.plot(xx, cubspline(xx), label='cubic');
plt.legend();

- Change the number of knots to 100 and see what happens. What would happen if we run a polynomial model of degree equal to the number of knots (a global one as in polynomial regression, not a spline)?
- What makes a spline 'Natural'?
B-Splines¶
A B-splines (Basis Splines) is defined by a set of control points and a set of basis functions that intepolate (fit) the function between these points. By choosing to have no smoothing factor we forces the final B-spline to pass though all the points. If, on the other hand, we set a smothing factor, our function is more of an approximation with the control points as "guidance". The latter produced a smoother curve which is prefferable for drawing software. For more on Splines see: https://en.wikipedia.org/wiki/B-spline)

We will use scipy.splrep to calulate the coefficients for the B-Spline and draw it.
B-Spline with no smooting¶
from scipy.interpolate import splev, splrep
x = np.linspace(0, 10, 10)
y = np.sin(x)
t,c,k = splrep(x, y) # (tck) is a tuple containing the vector of knots, coefficients, degree of the spline
print(t,c,k)
# define the points to plot on (x2)
x2 = np.linspace(0, 10, 200)
y2 = BSpline(t, c, k)
plt.plot(x, y, 'o', x2, y2(x2))
plt.show()

B-Spline with smooting factor s¶
from scipy.interpolate import splev, splrep
x = np.linspace(0, 10, 10)
y = np.sin(x)
s = 0.5 # add smooting factor
task = 0 # task needs to be set to 0, which represents:
# we are specifying a smoothing factor and thus only want
# splrep() to find the optimal t and c
t,c,k = splrep(x, y, task=task, s=s)
# define the points to plot on (x2)
x2 = np.linspace(0, 10, 200)
y2 = BSpline(t, c, k)
plt.plot(x, y, 'o', x2, y2(x2))
plt.show()

B-Spline with given knots¶
x = np.linspace(0, 10, 100)
y = np.sin(x)
knots = np.quantile(x, [0.25, 0.5, 0.75])
print(knots)
# calculate the B-Spline
t,c,k = splrep(x, y, t=knots)
curve = BSpline(t,c,k)
curve
plt.scatter(x=x,y=y,c='grey', alpha=0.4)
yknots = np.sin(knots)
plt.scatter(knots, yknots, c='r')
plt.plot(x,curve(x))
plt.show()

This example was similar with the Ed exercise. Open it in Ed and let's go though it.
3 - GAMs¶
https://readthedocs.org/projects/pygam/downloads/pdf/latest/
A - Classification in pyGAM¶
Let's get our (multivariate!) data, the kyphosis dataset, and the LogisticGAM model from pyGAM to do binary classification.
- kyphosis - wherther a particular deformation was present post-operation
- age - patient's age in months
- number - the number of vertebrae involved in the operation
- start - the number of the topmost vertebrae operated on
kyphosis = pd.read_csv("../data/kyphosis.csv")
display(kyphosis.head())
display(kyphosis.describe(include='all'))
display(kyphosis.dtypes)
# convert the outcome in a binary form, 1 or 0
kyphosis = pd.read_csv("../data/kyphosis.csv")
kyphosis["outcome"] = 1*(kyphosis["Kyphosis"] == "present")
kyphosis.describe()
from pygam import LogisticGAM, s, f, l
X = kyphosis[["Age","Number","Start"]]
y = kyphosis["outcome"]
kyph_gam = LogisticGAM().fit(X,y)
Outcome dependence on features¶
To help us see how the outcome depends on each feature, pyGAM has the partial_dependence() function.
pdep, confi = kyph_gam.partial_dependence(term=i, X=XX, width=0.95)For more on this see the : https://pygam.readthedocs.io/en/latest/api/logisticgam.html
res = kyph_gam.deviance_residuals(X,y)
for i, term in enumerate(kyph_gam.terms):
if term.isintercept:
continue
XX = kyph_gam.generate_X_grid(term=i)
pdep, confi = kyph_gam.partial_dependence(term=i, X=XX, width=0.95)
pdep2, _ = kyph_gam.partial_dependence(term=i, X=X, width=0.95)
plt.figure()
plt.scatter(X.iloc[:,term.feature], pdep2 + res)
plt.plot(XX[:, term.feature], pdep)
plt.plot(XX[:, term.feature], confi, c='r', ls='--')
plt.title(X.columns.values[term.feature])
plt.show()



Notice that we did not specify the basis functions in the .fit(). Cool. pyGAM figures them out for us by using $s()$ (splines) for numerical variables and $f()$ for categorical features. If this is not what we want we can manually specify the basis functions, as follows:
kyph_gam = LogisticGAM(s(0)+s(1)+s(2)).fit(X,y)
res = kyph_gam.deviance_residuals(X,y)
for i, term in enumerate(kyph_gam.terms):
if term.isintercept:
continue
XX = kyph_gam.generate_X_grid(term=i)
pdep, confi = kyph_gam.partial_dependence(term=i, X=XX, width=0.95)
pdep2, _ = kyph_gam.partial_dependence(term=i, X=X, width=0.95)
plt.figure()
plt.scatter(X.iloc[:,term.feature], pdep2 + res)
plt.plot(XX[:, term.feature], pdep)
plt.plot(XX[:, term.feature], confi, c='r', ls='--')
plt.title(X.columns.values[term.feature])
plt.show()
B - Regression in pyGAM¶
For regression problems, we can use a linearGAM model. For this part we will use the wages dataset.
The wages dataset¶
Let's inspect another dataset that is included in pyGAM that notes the wages of people based on their age, year of employment and education.
# from the pyGAM documentation
from pygam import LinearGAM, s, f
from pygam.datasets import wage
X, y = wage(return_X_y=True)
## model
gam = LinearGAM(s(0) + s(1) + f(2))
gam.gridsearch(X, y)
## plotting
plt.figure();
fig, axs = plt.subplots(1,3);
titles = ['year', 'age', 'education']
for i, ax in enumerate(axs):
XX = gam.generate_X_grid(term=i)
ax.plot(XX[:, i], gam.partial_dependence(term=i, X=XX))
ax.plot(XX[:, i], gam.partial_dependence(term=i, X=XX, width=.95)[1], c='r', ls='--')
if i == 0:
ax.set_ylim(-30,30)
ax.set_title(titles[i]);

What are your observations from the plots above?
4 - Smoothing Splines using pyGAM¶
For clarity: this is the fancy spline model that minimizes $MSE - \lambda\cdot\text{wiggle penalty}$ $=$ $\sum_{i=1}^N \left(y_i - f(x_i)\right)^2 - \lambda \int \left(f''(x)\right)^2$, across all possible functions $f$. The winner will always be a continuous, cubic polynomial with a knot at each data point.
Let's see how this smoothing works in pyGAM. We start by creating some arbitrary data and fitting them with a GAM.
X = np.linspace(0,10,500)
y = np.sin(X*2*np.pi)*X + np.random.randn(len(X))
plt.scatter(X,y);

# let's try a large lambda first and lots of splines
gam = LinearGAM(lam=1e6, n_splines=50). fit(X,y)
XX = gam.generate_X_grid(term=0)
plt.scatter(X,y,alpha=0.3);
plt.plot(XX, gam.predict(XX));

We see that the large $\lambda$ forces a straight line, no flexibility. Let's see now what happens if we make it smaller.
# let's try a smaller lambda
gam = LinearGAM(lam=1e2, n_splines=50). fit(X,y)
XX = gam.generate_X_grid(term=0)
plt.scatter(X,y,alpha=0.3);
plt.plot(XX, gam.predict(XX));

There is some curvature there but still not a good fit. Let's try no penalty. That should have the line fit exactly.
# no penalty, let's try a 0 lambda
gam = LinearGAM(lam=0, n_splines=50). fit(X,y)
XX = gam.generate_X_grid(term=0)
plt.scatter(X,y,alpha=0.3)
plt.plot(XX, gam.predict(XX))

Yes, that is good. Now let's see what happens if we lessen the number of splines. The fit should not be as good.
# no penalty, let's try a 0 lambda
gam = LinearGAM(lam=0, n_splines=10). fit(X,y)
XX = gam.generate_X_grid(term=0)
plt.scatter(X,y,alpha=0.3);
plt.plot(XX, gam.predict(XX));

Indeed.