Key Word(s): Requests, BeautifulSoup, Data Scraping
EDA, Pandas, and the Grammar of Data¶
We'd like a data structure that can represent the columns in the data above by their name. In particular, we want a structure that can easily store variables of different types, that stores column names, and that we can reference by column name as well as by indexed position. And it would be nice this data structure came with built-in functions that we can use to manipulate it.
Pandas is a package/library that does all of this! The library is built on top of numpy. There are two basic pandas objects, series and dataframes, which can be thought of as enhanced versions of 1D and 2D numpy arrays, respectively. Indeed Pandas attempts to keep all the efficiencies that numpy gives us.
For reference, here is a useful pandas cheat sheet and the pandas documentation.
The basic EDA workflow¶
Below is a basic checklist for the early stages of exploratory data analysis in Python. While not universally applicable, the rubric covers patterns which recur in several data analysis contexts, so useful to keep it in mind when encountering a new dataset.
The basic workflow (enunciated in this form by Chris Beaumont, the first Head TF of cs109 ever) is as follows:
- Build a Dataframe from the data (ideally, put all data in this object)
Clean the Dataframe. It should have the following properties:
- Each row describes a single object
- Each column describes a property of that object
- Columns are numeric whenever appropriate
- Columns contain atomic properties that cannot be further decomposed
Explore global properties. Use histograms, scatter plots, and aggregation functions to summarize the data.
- Explore group properties. Use groupby, queries, and small multiples to compare subsets of the data.
This process transforms the data into a format which is easier to work with, gives you a basic overview of the data's properties, and likely generates several questions for you to follow-up on in subsequent analysis.
# The %... is an iPython thing, and is not part of the Python language.
# In this case we're just telling the plotting library to draw things on
# the notebook, instead of on a separate window.
%matplotlib inline
# See all the "as ..." contructs? They're just aliasing the package names.
# That way we can call methods like plt.plot() instead of matplotlib.pyplot.plot().
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
import time
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn as sns
sns.set_style("whitegrid")
sns.set_context("poster")
Building a dataframe¶
The easiest way to build a dataframe is simply to read in a CSV file. We saw an example of this in lab, and we shall see 2 examples here. We'll also see how we may combine multiple data sources into a larger dataframe.
This example is adapted from: https://github.com/tthibo/SQL-Tutorial
The first 3 lines of the file (!head -3 data/candidates.txt on mac/unix) look like this.
id|first_name|last_name|middle_name|party
33|Joseph|Biden||D
36|Samuel|Brownback||Rdfcand=pd.read_csv("./data/candidates.txt", sep='|')
dfcand.head()
A pandas dataframe is a set of columns pasted together into a spreadsheet, as shown in the schematic below, which is taken from the cheatsheet above. The columns in pandas are called series objects.

All the columns in this dataframe:
dfcand.columns
And the types of these columns:
dfcand.dtypes
Access to a particular column can be obtained by treating the column name as an "attribute" of the dataframe:
dfcand.first_name
But Pandas supports a dictionary like access to columns. This is very useful when column names have spaces: Python variables cannot have spaces in them.
dfcand['first_name']
We can also get sub-dataframes by choosing a set of series. We pass a list of the columns we want as "dictionary keys" to the dataframe.
columns_i_want=['first_name', 'last_name']
dfcand[columns_i_want]
Categoricals¶
Even though party is a string, it takes on only a finite set of values, 'D', and 'R'. We can model this:
dfcand.party.unique()
dfcand['party'] = dfcand['party'].astype("category")
dfcand.dtypes
dfcand.head()
dfcand.party.describe()
dfcand.party.cat.categories
dfcand.party.cat.ordered
Keep in mind that this is a relatively new feature of Pandas. You dont need to do this, but might find it useful to keep your types straight. (Using categoricals in machine learning algorithms is more complex and usually involves a process called One Hot Encoding)
Another piece of data¶
This is a file of people who have contributed money to candidates:
(!head -3 data/contributors_with_candidate_id.txt)
id|last_name|first_name|middle_name|street_1|street_2|city|state|zip|amount|date|candidate_id
|Agee|Steven||549 Laurel Branch Road||Floyd|VA|24091|500.00|2007-06-30|16
|Ahrens|Don||4034 Rennellwood Way||Pleasanton|CA|94566|250.00|2007-05-16|16dfcwci=pd.read_csv("./data/contributors_with_candidate_id.txt", sep="|")
dfcwci.head()
Cleaning Data¶
most of the techniques you will learn about in Pandas are all about getting data in a form that can be used for further analysis. Cleaning usually means dealing with missing values, transforming types appropriately, and taking care of data integrity. But we'll lump everything required to transform data to a form appropriate for analysis cleaning, even if what we are doing is for example, combining multiple data sets, or producing processed data from raw data.
Lets start with some regular cleaning:
del dfcwci['id']
dfcwci.head()
We can see the size of our data
dfcwci.shape, dfcand.shape
We will do some more cleaning soon but let us see the EDA process as sliced from another angle: data transformation, used both for cleaning and for seeing single column and multiple column properties in the data.
Data transformation: Single Table Verbs¶
Let us now focus on core data manipulation commands. These are universal across systems, and by identifying them, we can quickly ask how to do these when we encounter a new system.
See https://gist.github.com/TomAugspurger/6e052140eaa5fdb6e8c0/ which has a comparison of r/dplyr and pandas. I stole and modified this table from there:
dplyr has a small set of nicely defined verbs, which Hadley Wickham has used to identify core data manipulation commands. Here are listed the closest SQL and Pandas verbs, so we can see the universality of these manipulations.
| VERB | dplyr | pandas | SQL |
|---|---|---|---|
| QUERY/SELECTION | filter() (and slice()) | query() (and loc[], iloc[]) | SELECT WHERE |
| SORT | arrange() | sort() | ORDER BY |
| SELECT-COLUMNS/PROJECTION | select() (and rename()) | [](__getitem__) (and rename()) | SELECT COLUMN |
| SELECT-DISTINCT | distinct() | unique(),drop_duplicates() | SELECT DISTINCT COLUMN |
| ASSIGN | mutate() (and transmute()) | assign | ALTER/UPDATE |
| AGGREGATE | summarise() | describe(), mean(), max() | None, AVG(),MAX() |
| SAMPLE | sample_n() and sample_frac() | sample() | implementation dep, use RAND() |
| GROUP-AGG | group_by/summarize | groupby/agg, count, mean | GROUP BY |
| DELETE | ? | drop/masking | DELETE/WHERE |
We'll tackle these one by one in Pandas, since these are data manipulations you will do all the time.
QUERY¶
dfcwci.amount < 400
This gives us Trues and Falses. Such a series is called a mask. A mask is the basis of filtering. We can do:
dfcwci[dfcwci.amount < 400].head()
Notice that the dataframe has been filtered down to only include those contributions with amount < 400. The rows with False in the mask have been eliminated, and those with True in the mask have been kept.
np.sum(dfcwci.amount < 400), np.mean(dfcwci.amount < 400)
Why did that work? The booleans are coerced to integers as below:
1*True, 1*False
Or directly, in Pandas, which works since the comparison is a pandas Series.
(dfcwci.amount < 400).mean()
You can combine queries. Note that we use Python's & operator instead of and. This is because we are "Boolean AND"ing masks to get a series of True's And Falses.
dfcwci[(dfcwci.state=='VA') & (dfcwci.amount < 400)]
Here is another way to write the query:
dfcwci.query("state=='VA' & amount < 400")
For cleaning, we might want to use this querying ability
dfcwci[dfcwci.state.isnull()]
Or the opposite, which is probably more useful in making the selection:
dfcwci[dfcwci.state.notnull()].head()
For categoricals you can use isin. You can use Boolean not on the mask to implement not in.
dfcwci[dfcwci.state.isin(['VA','WA'])].head(10)
And you can chain queries thus.
dfcwci.query("10 <= amount <= 50").head(10)
SORT¶
dfcwci.sort_values(by="amount").head(10)
dfcwci[dfcwci.amount < 0]
dfcwci.sort_values(by="amount", ascending=False).head(10)
SELECT-COLUMNS¶
dfcwci[['first_name', 'amount']].head(10)
SELECT-DISTINCT¶
Selecting a distinct set is useful for cleaning. Here, we might wish to focus on contributors rather than contributions and see how many distinct contributors we have. Of-course we might be wrong, some people have identical names.
dfcwci[['last_name','first_name']].count()
dfcwci[['last_name','first_name']].drop_duplicates().count()
dfcwci[['last_name','first_name']].drop_duplicates().head(10)
ASSIGN¶
Assignment to a new column is easy.
dfcwci['name']=dfcwci['last_name']+", "+dfcwci['first_name']
dfcwci.head(10)
dfcwci.assign(ucname=dfcwci.last_name+":"+dfcwci.first_name).head(10)
Will the above command actually change dfcwci?. No, it produces a fresh dataframe.
What if we wanted to change an existing assignment?¶
dfcwci[dfcwci.state=='VA']
dfcwci.loc[dfcwci.state=='VA', 'name']
dfcwci.loc[dfcwci.state=='VA', 'name']="junk"
dfcwci.query("state=='VA'")
Drop-Column¶
Real simple:
del dfcwci['name']
AGGREGATE¶
dfcwci.describe()
dfcwci.amount.max()
dfcwci[dfcwci.amount==dfcwci.amount.max()]
dfcwci[dfcwci.amount > dfcwci.amount.max() - 2300]
Aso MIN, SUM, AVG.
Grouping using Pandas and split-apply-combine¶
grouped_by_state = dfcwci.groupby("state")
grouped_by_state
grouped_by_state.amount
How do we get access to these? Standard pandas functions distribute over the groupby, going one by one over the sub-dataframes or sub-series. This is an example of a paradigm called split-apply-combine.
GROUP-AGG¶
The fourth part of the EDA rubric is to look at properties of the sub-dataframes you get when you make groups. (We'll talk about the graphical aspects of this later). For instance, you might group contributions by state:
dfcwci.groupby("state").describe()
dfcwci.groupby("state").sum()
dfcwci.groupby("state")['amount'].mean()
dfcwci.groupby("state")['amount'].apply(lambda x: np.std(x))
The dictionary-like structure is more obvious in this method of iteration, but it does not do the combining part...
for k, v in dfcwci.groupby('state'):
print("State", k, "mean amount", v.amount.mean(), "std", v.amount.std())
DELETE¶
dfcwci.head()
In-place drops
df2=dfcwci.copy()
df2.set_index('last_name', inplace=True)
df2.head()
df2.drop(['Ahrens'], inplace=True)
df2.head()
df2.reset_index(inplace=True)
df2.head()
The recommended way to do it is to create a new dataframe. This might be impractical is things are very large.
dfcwci=dfcwci[dfcwci.last_name!='Ahrens']
dfcwci.head(10)
LIMIT¶
dfcwci[0:3] # also see loc and iloc from the lab
Relationships: JOINs are Cartesian Products.¶
Finally, there are many occasions you will want to combine dataframes. We might want to see who contributed to Obama:
Simple subselect¶
dfcand.head()
obamaid=dfcand.query("last_name=='Obama'")['id'].values[0]
obamacontrib=dfcwci.query("candidate_id==%i" % obamaid)
obamacontrib.head()
Explicit INNER JOIN¶
This is the one you will want 90% of the time. It will only match keys that are present in both dataframes.

cols_wanted=['last_name_x', 'first_name_x', 'candidate_id', 'id', 'last_name_y']
dfcwci.merge(dfcand, left_on="candidate_id", right_on="id")[cols_wanted]
If the names of the columns you wanted to merge on were identical, you could simply say on=id, for example, rather than a left_on and a right_on.
Outer JOIN¶
left outer (contributors on candidates)¶
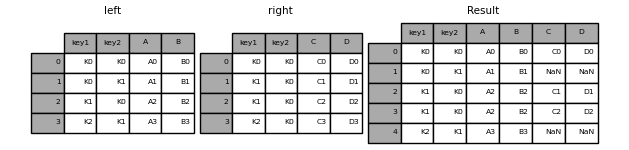
dfcwci.merge(dfcand, left_on="candidate_id", right_on="id", how="left")[cols_wanted]
right outer (contributors on candidates) = left outer (candidates on contributors)¶

dfcwci.merge(dfcand, left_on="candidate_id", right_on="id", how="right")[cols_wanted]
full outer¶
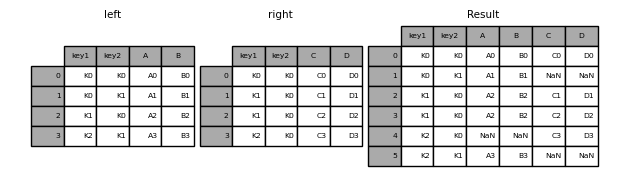
dfcwci.merge(dfcand, left_on="candidate_id", right_on="id", how="outer")[cols_wanted]