Key Word(s): Model Selection
Validation and Regularization¶

%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn.apionly as sns
sns.set_style("whitegrid")
sns.set_context("poster")
def make_simple_plot():
fig, axes=plt.subplots(figsize=(12,5), nrows=1, ncols=2);
axes[0].set_ylabel("$y$")
axes[0].set_xlabel("$x$")
axes[1].set_xlabel("$x$")
axes[1].set_yticklabels([])
axes[0].set_ylim([-2,2])
axes[1].set_ylim([-2,2])
plt.tight_layout();
return axes
def make_plot():
fig, axes=plt.subplots(figsize=(20,8), nrows=1, ncols=2);
axes[0].set_ylabel("$p_R$")
axes[0].set_xlabel("$x$")
axes[1].set_xlabel("$x$")
axes[1].set_yticklabels([])
axes[0].set_ylim([0,1])
axes[1].set_ylim([0,1])
axes[0].set_xlim([0,1])
axes[1].set_xlim([0,1])
plt.tight_layout();
return axes
PART 1: Reading in and sampling from the data¶
df=pd.read_csv("../data/noisypopulation.csv")
df.head()
x=df.f.values
f=df.x.values
y = df.y.values
df.shape
From 200 points on this curve, we'll make a random choice of 60 points. We do it by choosing the indexes randomly, and then using these indexes as a way of grtting the appropriate samples
indexes=np.sort(np.random.choice(x.shape[0], size=60, replace=False))
indexes
samplex = x[indexes]
samplef = f[indexes]
sampley = y[indexes]
plt.plot(x,f, 'k-', alpha=0.6, label="f");
plt.plot(x[indexes], y[indexes], 's', alpha=0.3, ms=10, label="in-sample y (observed)");
plt.plot(x, y, '.', alpha=0.8, label="population y");
plt.xlabel('$x$');
plt.ylabel('$y$')
plt.legend(loc=4);
sample_df=pd.DataFrame(dict(x=x[indexes],f=f[indexes],y=y[indexes]))
from sklearn.model_selection import train_test_split
datasize=sample_df.shape[0]
print(datasize)
#split dataset using the index, as we have x,f, and y that we want to split.
itrain,itest = train_test_split(np.arange(60),train_size=0.8)
print(itrain.shape)
xtrain= sample_df.x[itrain].values
ftrain = sample_df.f[itrain].values
ytrain = sample_df.y[itrain].values
xtest= sample_df.x[itest].values
ftest = sample_df.f[itest].values
ytest = sample_df.y[itest].values
sample_df.x[itrain].values
We'll need to create polynomial features, ie add 1, x, x^2 and so on.
The scikit-learn interface¶
Scikit-learn is the main python machine learning library. It consists of many learners which can learn models from data, as well as a lot of utility functions such as train_test_split. It can be used in python by the incantation import sklearn.
The library has a very well defined interface. This makes the library a joy to use, and surely contributes to its popularity. As the scikit-learn API paper [Buitinck, Lars, et al. "API design for machine learning software: experiences from the scikit-learn project." arXiv preprint arXiv:1309.0238 (2013).] says:
All objects within scikit-learn share a uniform common basic API consisting of three complementary interfaces: an estimator interface for building and fitting models, a predictor interface for making predictions and a transformer interface for converting data. The estimator interface is at the core of the library. It defines instantiation mechanisms of objects and exposes a
fitmethod for learning a model from training data. All supervised and unsupervised learning algorithms (e.g., for classification, regression or clustering) are offered as objects implementing this interface. Machine learning tasks like feature extraction, feature selection or dimensionality reduction are also provided as estimators.
We'll use the "estimator" interface here, specifically the estimator PolynomialFeatures. The API paper again:
Since it is common to modify or filter data before feeding it to a learning algorithm, some estimators in the library implement a transformer interface which defines a transform method. It takes as input some new data X and yields as output a transformed version of X. Preprocessing, feature selection, feature extraction and dimensionality reduction algorithms are all provided as transformers within the library.
To start with we have one feature x to predict y, what we will do is the transformation:
$$ x \rightarrow 1, x, x^2, x^3, ..., x^d $$
for some power $d$. Our job then is to fit for the coefficients of these features in the polynomial
$$ a_0 + a_1 x + a_2 x^2 + ... + a_d x^d. $$
In other words, we have transformed a function of one feature, into a (rather simple) linear function of many features. To do this we first construct the estimator as PolynomialFeatures(d), and then transform these features into a d-dimensional space using the method fit_transform.
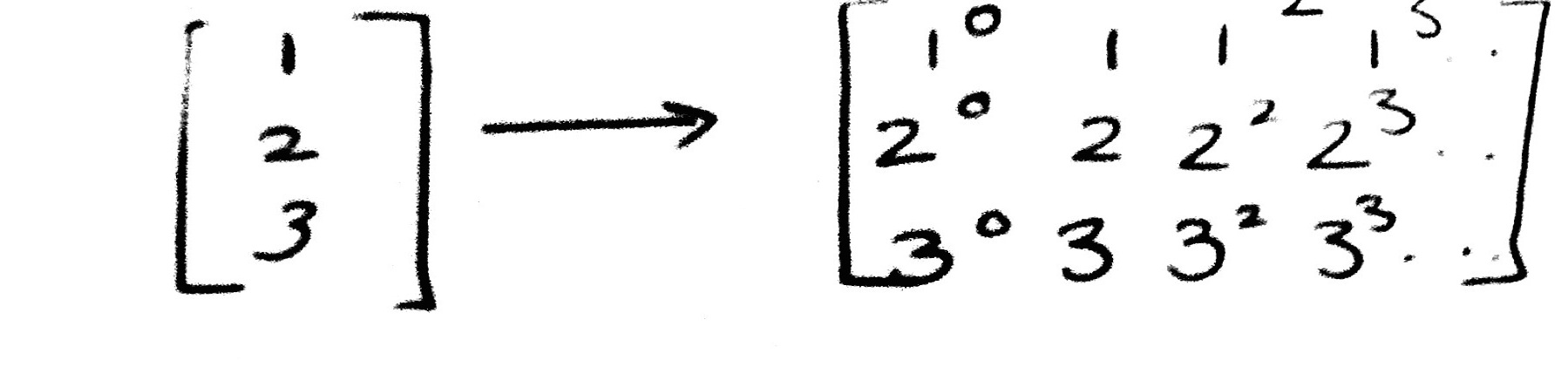
Here is an example. The reason for using [[1],[2],[3]] as opposed to [1,2,3] is that scikit-learn expects data to be stored in a two-dimensional array or matrix with size [n_samples, n_features].
np.array([1,2,3]).reshape(-1,1)
To transform [1,2,3] into [[1],[2],[3]] we need to do a reshape.

xtest.reshape(-1,1)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
PolynomialFeatures(3).fit_transform(xtest)
PolynomialFeatures(3).fit_transform(xtest.reshape(-1,1))
Creating Polynomial features¶
We'll write a function to encapsulate what we learnt about creating the polynomial features.
def make_features(train_set, test_set, degrees):
train_dict = {}
test_dict = {}
for d in degrees:
traintestdict={}
train_dict[d] = PolynomialFeatures(d).fit_transform(train_set.reshape(-1,1))
test_dict[d] = PolynomialFeatures(d).fit_transform(test_set.reshape(-1,1))
return train_dict, test_dict
Doing the fit¶
We first create our features, and some arrays to store the errors.
degrees=range(21)
train_dict, test_dict = make_features(xtrain, xtest, degrees)
error_train=np.empty(len(degrees))
error_test=np.empty(len(degrees))
What is the fitting process? We first loop over all the hypothesis sets that we wish to consider: in our case this is a loop over the complexity parameter $d$, the degree of the polynomials we will try and fit. That is we start with ${\cal H_0}$, the set of all 0th order polynomials, then do ${\cal H_1}$, then ${\cal H_2}$, and so on... We use the notation ${\cal H}$ to indicate a hypothesis set. Then for each degree $d$, we obtain a best fit model. We then "test" this model by predicting on the test chunk, obtaining the test set error for the best-fit polynomial coefficients and for degree $d$. We move on to the next degree $d$ and repeat the process, just like before. We compare all the test set errors, and pick the degree $d_*$ and the model in ${\cal H_{d_*}}$ which minimizes this test set error.
YOUR TURN HERE: For each degree d, train on the training set and predict on the test set. Store the training MSE in
error_trainand test MSE inerror_test.
#for each degree, we now fit on the training set and predict on the test set
#we accumulate the MSE on both sets in error_train and error_test
for d in degrees:#for increasing polynomial degrees 0,1,2...
Xtrain = train_dict[d]
Xtest = test_dict[d]
#set up model
est = LinearRegression()
#fit
est.fit(Xtrain, ytrain)
#predict
#your code here
We can find the best degree thus:
bestd = np.argmin(error_test)
plt.plot(degrees, error_train, marker='o', label='train (in-sample)')
plt.plot(degrees, error_test, marker='o', label='test')
plt.axvline(bestd, 0,0.5, color='r', label="min test error at d=%d"%bestd, alpha=0.3)
plt.ylabel('mean squared error')
plt.xlabel('degree')
plt.legend(loc='upper left')
plt.yscale("log")
Validation¶
What we have done in picking a given $d$ as the best hypothesis is that we have used the test set as a training set. If we choose the best $d$ based on minimizing the test set error, we have then "fit for" hyperparameter $d$ on the test set.
In this case, the test-set error will underestimate the true out of sample error. Furthermore, we have contaminated the test set by fitting for $d$ on it; it is no longer a true test set.
Thus, we introduce a new validation set on which the complexity parameter $d$ is fit, and leave out a test set which we can use to estimate the true out-of-sample performance of our learner. The place of this set in the scheme of things is shown below:
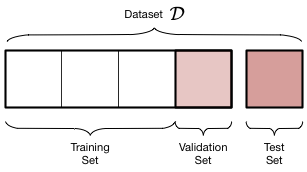
We have split the old training set into a new smaller training set and a validation set, holding the old test aside for FINAL testing AFTER we have "fit" for complexity $d$. Obviously we have decreased the size of the data available for training further, but this is a price we must pay for obtaining a good estimate of the out-of-sample risk $\cal{E}_{out}$ (also denoted as risk $R_{out}$) through the test risk $\cal{E}_{test}$ ($R_{test}$).
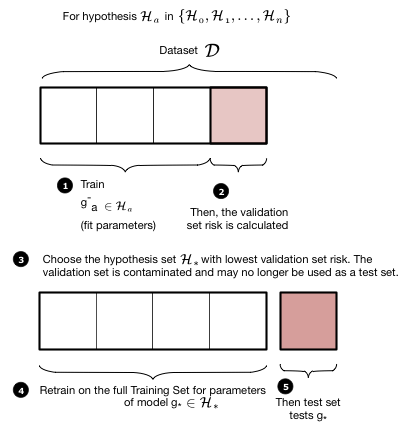
The validation process is illustrated in these two figures. We first loop over the complexity parameter $d$, the degree of the polynomials we will try and fit. Then for each degree $d$, we obtain a best fit model $g^-_d$ where the "minus" superscript indicates that we fit our model on the new training set which is obtained by removing ("minusing") a validation chunk (often the same size as the test chunk) from the old training set. We then "test" this model on the validation chunk, obtaining the validation error for the best-fit polynomial coefficients and for degree $d$. We move on to the next degree $d$ and repeat the process, just like before. We compare all the validation set errors, just like we did with the test errors earlier, and pick the degree $d_*$ which minimizes this validation set error.
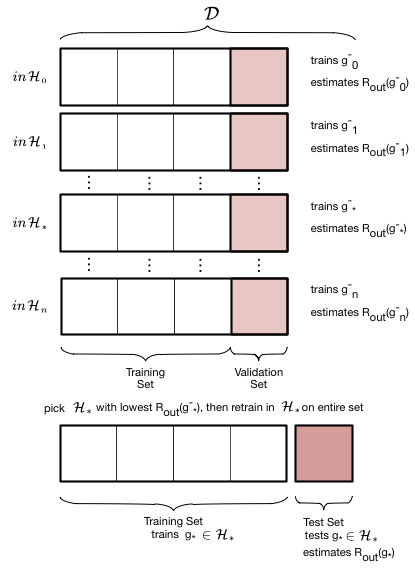
Having picked the hyperparameter $d_*$, we retrain using the hypothesis set $\cal{H}_{*}$ on the entire old training-set to find the parameters of the polynomial of order $d_*$ and the corresponding best fit hypothesis $g_*$. Note that we left the minus off the $g$ to indicate that it was trained on the entire old traing set. We now compute the test error on the test set as an estimate of the test risk $\cal{E}_{test}$.
Thus the validation set if the set on which the hyperparameter is fit. This method of splitting the data $\cal{D}$ is called the train-validate-test split.
Fit on training and predict on validation¶
We carry out this process for one training/validation split below. Note the smaller size of the new training set. We hold the test set at the same size.
#we split the training set down further
intrain,invalid = train_test_split(itrain,train_size=36, test_size=12)
# why not just use xtrain, xtest here? its the indices we need. How could you use xtrain and xtest?
xntrain= sample_df.x[intrain].values
fntrain = sample_df.f[intrain].values
yntrain = sample_df.y[intrain].values
xnvalid= sample_df.x[invalid].values
fnvalid = sample_df.f[invalid].values
ynvalid = sample_df.y[invalid].values
degrees=range(21)
train_dict, valid_dict = make_features(xntrain, xnvalid, degrees)
YOUR TURN HERE: Train on the smaller training set. Fit for d on the validation set. Store the respective MSEs in
error_trainanderror_valid. Then retrain on the entire training set using this d. Label the test set MSE with the variableerr.
error_train=np.empty(len(degrees))
error_valid=np.empty(len(degrees))
#for each degree, we now fit on the smaller training set and predict on the validation set
#we accumulate the MSE on both sets in error_train and error_valid
#we then find the degree of polynomial that minimizes the MSE on the validation set.
#your code here
#calculate the degree at which validation error is minimized
mindeg = np.argmin(error_valid)
mindeg
#fit on WHOLE training set now.
##you will need to remake polynomial features on the whole training set
#Put MSE on the test set in variable err.
#your code here
We plot the training error and validation error against the degree of the polynomial, and show the test set error at the $d$ which minimizes the validation set error.
plt.plot(degrees, error_train, marker='o', label='train (in-sample)')
plt.plot(degrees, error_valid, marker='o', label='validation')
plt.plot([mindeg], [err], marker='s', markersize=10, label='test', alpha=0.5, color='r')
plt.ylabel('mean squared error')
plt.xlabel('degree')
plt.legend(loc='upper left')
plt.yscale("log")
print(mindeg)
Run the set of cells for the validation process again and again. What do you see? The validation error minimizing polynomial degree might change! What happened?
Cross Validation¶
- You should worry that a given split exposes us to the peculiarity of the data set that got randomly chosen for us. This naturally leads us to want to choose multiple such random splits and somehow average over this process to find the "best" validation minimizing polynomial degree or complexity $d$.
- The multiple splits process also allows us to get an estimate of how consistent our prediction error is: in other words, just like in the hair example, it gives us a distribution.
- Furthermore the validation set that we left out has two competing demands on it. The larger the set is, the better is our estimate of the out-of-sample error. So we'd like to hold out as much as possible. But the smaller the validation set is, the more data we have to train our model on. This allows us to have more smaller sets
The idea is illustrated in the figure below, for a given hypothesis set $\cal{H}_a$ with complexity parameter $d=a$ (the polynomial degree). We do the train/validate split, not once but multiple times.
In the figure below we create 4-folds from the training set part of our data set $\cal{D}$. By this we mean that we divide our set roughly into 4 equal parts. As illustrated below, this can be done in 4 different ways, or folds. In each fold we train a model on 3 of the parts. The model so trained is denoted as $g^-_{Fi}$, for example $g^-_{F3}$ . The minus sign in the superscript once again indicates that we are training on a reduced set. The $F3$ indicates that this model was trained on the third fold. Note that the model trained on each fold will be different!
For each fold, after training the model, we calculate the risk or error on the remaining one validation part. We then add the validation errors together from the different folds, and divide by the number of folds to calculate an average error. Note again that this average error is an average over different models $g^-_{Fi}$. We use this error as the validation error for $d=a$ in the validation process described earlier.
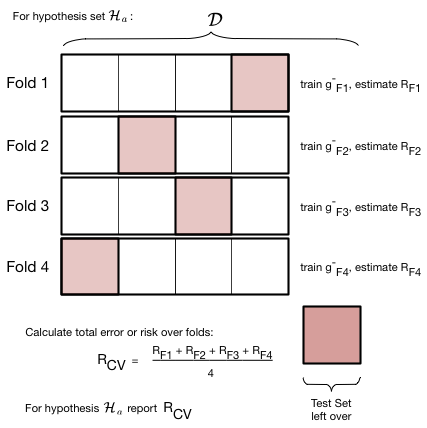
Note that the number of folds is equal to the number of splits in the data. For example, if we have 5 splits, there will be 5 folds. To illustrate cross-validation consider below fits in $\cal{H}_0$ and $\cal{H}_1$ (means and straight lines) to a sine curve, with only 3 data points.
The entire description of K-fold Cross-validation¶
We put thogether this scheme to calculate the error for a given polynomial degree $d$ with the method we used earlier to choose a model given the validation-set risk as a function of $d$:
- create
n_foldspartitions of the training data. - We then train on
n_folds -1of these partitions, and test on the remaining partition. There aren_foldssuch combinations of partitions (or folds), and thus we obtainn_foldrisks. - We average the error or risk of all such combinations to obtain, for each value of $d$, $R_{dCV}$.
- We move on to the next value of $d$, and repeat 3
- and then find the optimal value of d that minimizes risk $d=*$.
- We finally use that value to make the final fit in $\cal{H}_*$ on the entire old training set.
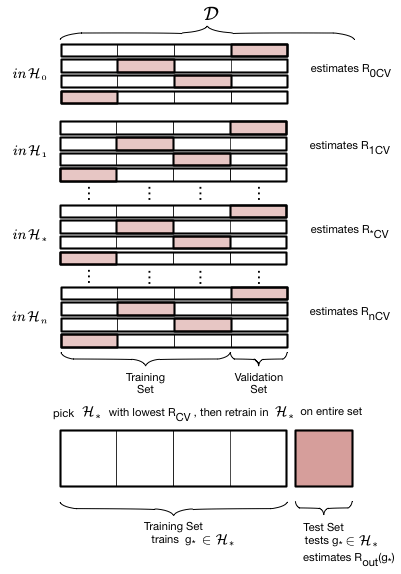
It can also shown that cross-validation error is an unbiased estimate of the out of sample-error.
Let us now do 4-fold cross-validation on our data set. We increase the complexity from degree 0 to degree 20. In each case we take the old training set, split in 4 ways into 4 folds, train on 3 folds, and calculate the validation error on the remaining one. We then average the erros over the four folds to get a cross-validation error for that $d$. Then we did what we did before: find the hypothesis space $\cal{H}_*$ with the lowest cross-validation error, and refit it using the entire training set. We can then use the test set to estimate $E_{out}$.
We will use KFold from scikit-learn:
from sklearn.model_selection import KFold
n_folds=4
kfold = KFold(n_folds)
list(kfold.split(range(48)))
What is wrong with the above? Why must we do the below?
kfold = KFold(n_folds, shuffle=True)
list(kfold.split(range(48)))
4-fold CV on our data set¶
YOUR TURN HERE: Carry out 4-Fold validation. For each fold, you will need to first create the polynomial features. for each degree polynomial, fit on the smaller training set and predict on the validation set. Store the MSEs, for each degree and each fold, in
train_errorsandvalid_errors.
n_folds=4
degrees=range(21)
train_errors = np.zeros((21,4))
valid_errors = np.zeros((21,4))
# your code here
We average the MSEs over the folds
mean_train_errors = train_errors.mean(axis=1)
mean_valid_errors = valid_errors.mean(axis=1)
std_train_errors = train_errors.std(axis=1)
std_valid_errors = valid_errors.std(axis=1)
We find the degree that minimizes the cross-validation error, and just like before, refit the model on the entire training set
mindeg = np.argmin(mean_valid_errors)
print(mindeg)
post_cv_train_dict, test_dict=make_features(xtrain, xtest, degrees)
#fit on whole training set now.
est = LinearRegression()
est.fit(post_cv_train_dict[mindeg], ytrain) # fit
pred = est.predict(test_dict[mindeg])
err = mean_squared_error(pred, ytest)
errtr=mean_squared_error(ytrain, est.predict(post_cv_train_dict[mindeg]))
c0=sns.color_palette()[0]
c1=sns.color_palette()[1]
#plt.errorbar(degrees, [r[0] for r in results], yerr=[r[3] for r in results], marker='o', label='CV error', alpha=0.5)
plt.plot(degrees, mean_train_errors, marker='o', label='CV error', alpha=0.9)
plt.plot(degrees, mean_valid_errors, marker='o', label='CV error', alpha=0.9)
plt.fill_between(degrees, mean_valid_errors-std_valid_errors, mean_valid_errors+std_valid_errors, color=c1, alpha=0.2)
plt.plot([mindeg], [err], 'o', label='test set error')
plt.ylabel('mean squared error')
plt.xlabel('degree')
plt.legend(loc='upper right')
plt.yscale("log")
We see that the cross-validation error minimizes at a low degree, and then increases. Because we have so few data points the spread in fold errors increases as well.
Regularization¶
Upto now we have focussed on finding the polynomial with the right degree of complecity $d=*$ given the data that we have.
When we regularize we smooth or restrict the choices of the kinds of 20th order polynomials that we allow in our fits.
That is, if we want to fit with a 20th order polynomial, ok, lets fit with it, but lets reduce the size of, or limit the functions in $\cal{H}_{20}$ that we allow.
We do this by a soft constraint by setting:
$$\sum_{i=0}^j a_i^2 < C.$$
This setting is called the Ridge.
This ensures that the coefficients dont get too high, which makes sure we dont get wildly behaving pilynomials with high coefficients.
It turns out that we can do this by adding a term to the risk that we minimize on the training data for $\cal{H}_j$ (seeing why is beyond the scope here but google on lagrange multipliers and the dual problem):
$$\cal{R}(h_j) = \sum_{y_i \in \cal{D}} (y_i - h_j(x_i))^2 +\alpha \sum_{i=0}^j a_i^2.$$
Regularization of our model with Cross-Validation¶
def plot_functions(d, est, ax, df, alpha, xtest, Xtest, xtrain, ytrain):
"""Plot the approximation of ``est`` on axis ``ax``. """
ax.plot(df.x, df.f, color='k', label='f')
ax.plot(xtrain, ytrain, 's', label="training", ms=5, alpha=0.3)
ax.plot(xtest, ytest, 's', label="testing", ms=5, alpha=0.3)
transx=np.arange(0,1.1,0.01)
transX = PolynomialFeatures(d).fit_transform(transx.reshape(-1,1))
ax.plot(transx, est.predict(transX), '.', ms=7, alpha=0.8, label="alpha = %s" % str(alpha))
ax.set_ylim((0, 1))
ax.set_xlim((0, 1))
ax.set_ylabel('y')
ax.set_xlabel('x')
ax.legend(loc='lower right')
def plot_coefficients(est, ax, alpha):
coef = est.coef_.ravel()
ax.semilogy(np.abs(coef), marker='o', label="alpha = %s" % str(alpha))
ax.set_ylim((1e-1, 1e15))
ax.set_ylabel('abs(coefficient)')
ax.set_xlabel('coefficients')
ax.legend(loc='upper left')
The addition of a penalty term to the risk or error causes us to choose a smaller subset of the entire set of complex $\cal{H}_{20}$ polynomials. This is shown in the diagram below where the balance between bias and variance occurs at some subset $S_*$ of the set of 20th order polynomials indexed by $\alpha_*$ (there is an error on the diagram, the 13 there should actually be a 20).

Lets see what some of the $\alpha$s do. The diagram below trains on the entire training set, for given values of $\alpha$, minimizing the penalty-term-added training error.
Note that here we are doing the note so good thing of exhausting the test set for demonstration purposes
from sklearn.linear_model import Ridge
fig, rows = plt.subplots(6, 2, figsize=(12, 24))
d=20
alphas = [0.0, 1e-6, 1e-5, 1e-3, 0.01, 1]
train_dict, test_dict = make_features(xtrain, xtest, degrees)
Xtrain = train_dict[d]
Xtest = test_dict[d]
for i, alpha in enumerate(alphas):
l,r=rows[i]
est = Ridge(alpha=alpha)
est.fit(Xtrain, ytrain)
plot_functions(d, est, l, df, alpha, xtest, Xtest, xtrain, ytrain )
plot_coefficients(est, r, alpha)
As you can see, as we increase $\alpha$ from 0 to 1, we start out overfitting, then doing well, and then, our fits, develop a mind of their own irrespective of data, as the penalty term dominates the risk.
GridSearchCV meta-estimator¶
Lets use cross-validation to figure what this critical $\alpha_*$ is. To do this we use the concept of a meta-estimator from scikit-learn. As the API paper puts it:
In scikit-learn, model selection is supported in two distinct meta-estimators, GridSearchCV and RandomizedSearchCV. They take as input an estimator (basic or composite), whose hyper-parameters must be optimized, and a set of hyperparameter settings to search through.
The concept of a meta-estimator allows us to wrap, for example, cross-validation, or methods that build and combine simpler models or schemes. For example:
est = Ridge()
parameters = {"alpha": [1e-8, 1e-6, 1e-5, 5e-5, 1e-4, 5e-4, 1e-3, 1e-2, 1e-1, 1.0]}
gridclassifier=GridSearchCV(est, param_grid=parameters, cv=4, scoring="mean_squared_error")
The GridSearchCV replaces the manual iteration over thefolds using KFolds and the averaging we did previously, doing it all for us. It takes a parameter grid in the shape of a dictionary as input, and sets $\alpha$ to the appropriate parameter values one by one. It then trains the model, cross-validation fashion, and gets the error. Finally it compares the errors for the different $\alpha$'s, and picks the best choice model.
from sklearn.model_selection import GridSearchCV
def cv_optimize_ridge(X, y, n_folds=4):
est = Ridge()
parameters = {"alpha": [1e-8, 1e-6, 1e-5, 5e-5, 1e-4, 5e-4, 1e-3, 1e-2, 1e-1, 1.0]}
#the scoring parameter below is the default one in ridge, but you can use a different one
#in the cross-validation phase if you want.
gs = GridSearchCV(est, param_grid=parameters, cv=n_folds, scoring="neg_mean_squared_error")
gs.fit(X, y)
return gs
fitmodel = cv_optimize_ridge(Xtrain, ytrain, n_folds=4)
fitmodel.best_estimator_, fitmodel.best_params_, fitmodel.best_score_
fitmodel.cv_results_
Our best model occurs for $\alpha=0.01$. We also output the mean cross-validation error at different $\alpha$ (with a negative sign, as scikit-learn likes to maximize negative error which is equivalent to minimizing error).
Refitting on entire training set¶
We refit the estimator on old training set, and calculate and plot the test set error and the polynomial coefficients. Notice how many of these coefficients have been pushed to lower values or 0.
YOUR TURN NOW: assign to variable est the classifier obtained by fitting the entire training set using the best $\alpha$ found above.
#Store in est a new classifier fit on the entire training set with the best alpha
#your code here
def plot_functions_onall(est, ax, df, alpha, xtrain, ytrain, Xtrain, xtest, ytest):
"""Plot the approximation of ``est`` on axis ``ax``. """
ax.plot(df.x, df.f, color='k', label='f')
ax.plot(xtrain, ytrain, 's', alpha=0.4, label="train")
ax.plot(xtest, ytest, 's', alpha=0.6, label="test")
transx=np.arange(0,1.1,0.01)
transX = PolynomialFeatures(20).fit_transform(transx.reshape(-1,1))
ax.plot(transx, est.predict(transX), '.', alpha=0.6, label="alpha = %s" % str(alpha))
#print est.predict(transX)
ax.set_ylim((0, 1))
ax.set_xlim((0, 1))
ax.set_ylabel('y')
ax.set_xlabel('x')
ax.legend(loc='lower right')
fig, rows = plt.subplots(1, 2, figsize=(12, 5))
l,r=rows
plot_functions_onall(est, l, df, alphawechoose, xtrain, ytrain, Xtrain, xtest, ytest)
plot_coefficients(est, r, alphawechoose)
As we can see, the best fit model is now chosen from the entire set of 20th order polynomials, and a non-zero hyperparameter $\alpha$ that we fit for ensures that only smooth models amonst these polynomials are chosen, by setting most of the polynomial coefficients to something close to 0 (Lasson sets them exactly to 0).
Why do we seem to need a larger alpha than before?