Key Word(s): Linear Regression
Table of Contents¶
- Linear regression with a toy - matrices and math
- Simple linear regression with automobile data
- Multiple linear regression with automobile data
- Interpreting results
- building a model from scratch
- building a model with statsmodel and sklearn
This lab maps on to lectures 3, 4, 5 and homework 2.
Part 1: Linear regression with a toy¶
We first examine a toy problem, focusing our efforts on fitting a linear model to a small dataset with three observations. Each observation consists of one predictor $x_i$ and one response $y_i$ for $i = 1, 2, 3$,
\begin{equation*} (x , y) = \{(x_1, y_1), (x_2, y_2), (x_3, y_3)\}. \end{equation*}
To be very concrete, let's set the values of the predictors and responses.
\begin{equation*} (x , y) = \{(1, 2), (2, 2), (3, 4)\} \end{equation*}
There is no line of the form $\beta_0 + \beta_1 x = y$ that passes through all three observations, since the data is not collinear. Thus our aim is to find the line that best fits these observations in the least-squares sense, as discussed in lecture.
Matrices and math [10 minutes]¶
Suspending reality, suppose there is a line $\beta_0 + \beta_1 x = y$ that passes through all three observations. Then we'd solve
\begin{eqnarray} \beta_0 + \beta_1 &=& 2 \nonumber \\ \beta_0 + 2 \beta_1 &=& 2 \nonumber \\ \beta_0 + 3 \beta_1 &=& 4, \nonumber \\ \end{eqnarray}
for $\beta_0$ and $\beta_1$, the intercept and slope of the desired line. Let's write these equations in matrix form. The left hand sides of the above equations can be written as
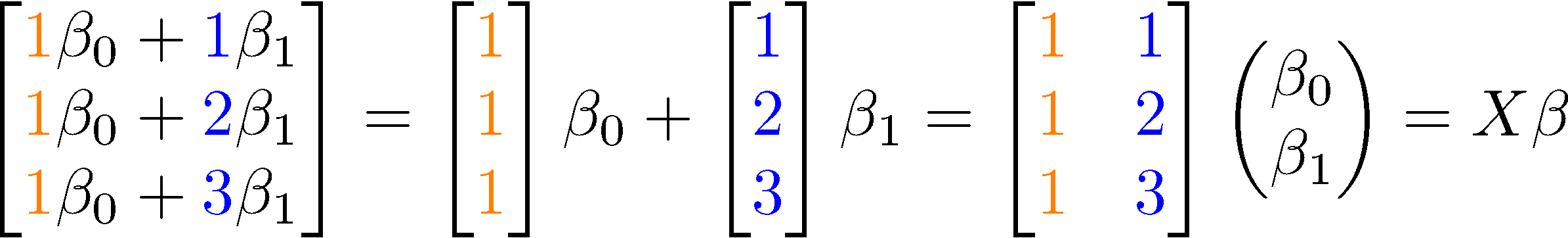
while the right hand side is simply the vector
\begin{equation*}Y = \begin{bmatrix} 2 \\ 2 \\ 4 \end{bmatrix}. \end{equation*}
Thus we have the matrix equation $X \beta = Y$ where
\begin{equation} X = \begin{bmatrix} 1 & 1\\ 1 & 2\\ 1 & 3 \end{bmatrix}, \quad \beta = \begin{pmatrix} \beta_0 \\ \beta_1 \end{pmatrix}, \quad \mathrm{and} \quad Y = \begin{bmatrix} 2 \\ 2 \\ 4 \end{bmatrix}. \end{equation}
To find the best possible solution to this linear system that has no solution, we need to solve the normal equations, or
\begin{equation} X^T X \beta = X^T Y. \end{equation}
If $X^T X$ is invertible then the solution is
\begin{equation} \beta = (X^T X)^{-1} X^T Y. \end{equation}
EXERCISE: What if the toy problem included a second predictor variable? How would $X, \beta$, and $Y$ change, if at all? Would anything else change? Create a new markdown cell below and explain.
Building a model from scratch [15 minutes]¶
We now solve the normal equations to find the best fit solution to our toy problem. Note that we have constructed our toy problem so that $X^T X$ is invertible. Let's import the needed modules. Note that we've imported statsmodels and sklearn in this below, which we'll use to build regression models.
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn import linear_model, datasets
import matplotlib.pyplot as plt
import statsmodels.api as sm
%matplotlib inline
The snippets of code below solves the equations using the observed predictors and responses, which we'll call the training data set. Let's walk through the code.
#observed predictors
x_train = np.array([1, 2, 3])
print(x_train.shape)
x_train = x_train.reshape(len(x_train),1)
#check dimensions
print(x_train.shape)
#observed responses
y_train = np.array([2, 2, 4])
y_train = y_train.reshape(len(y_train),1)
print(y_train.shape)
#build matrix X by concatenating predictors and a column of ones
n = x_train.shape[0]
ones_col = np.ones((n, 1))
X = np.concatenate((ones_col, x_train), axis=1)
#check X and dimensions
print(X, X.shape)
#matrix X^T X
LHS = np.dot(np.transpose(X), X)
#matrix X^T Y
RHS = np.dot(np.transpose(X), y_train)
#solution beta to normal equations, since LHS is invertible by toy construction
betas = np.dot(np.linalg.inv(LHS), RHS)
#intercept beta0
beta0 = betas[0]
#slope beta1
beta1 = betas[1]
print(beta0, beta1)
EXERCISE: Turn the code from the above cells into a function, called
simple_linear_regression_fit, that inputs the training data and returnsbeta0andbeta1.To do this, copy and paste the code from the above cells below and adjust the code as needed, so that the training data becomes the input and the betas become the output.
Check your function by calling it with the training data from above and printing out the beta values.
#your code here
def simple_linear_regression_fit(x_train, y_train):
return
EXERCISE: Plot the training data. Do the values of
beta0andbeta1seem reasonable?Now write a lambda function
ffor the best fit line withbeta0andbeta1, and plot the best fit line together with the training data.
#your code here
Building a model with statsmodel and sklearn [10 minutes]¶
Now that we can concretely fit the training data from scratch, let's learn two Python packages to do it all for us: statsmodels and scikit-learn (sklearn). Our goal is to show how to implement simple linear regression with these packages. For an important sanity check, we compare the $\beta$ values from statsmodel and sklearn to the $\beta$ values that we found from above from scratch.
For the purposes of this lab, statsmodels and sklearn do the same thing. More generally though, statsmodels tends to be easier for inference, whereas sklearn has machine-learning algorithms and is better for prediction.
Below is the code for statsmodels. Statsmodels does not by default include the column of ones in the $X$ matrix, so we include it with sm.add_constant.
#create the X matrix by appending a column of ones to x_train
X = sm.add_constant(x_train)
#this is the same matrix as in our scratch problem!
print(X)
#build the OLS model (ordinary least squares) from the training data
toyregr_sm = sm.OLS(y_train, X)
#save regression info (parameters, etc) in results_sm
results_sm = toyregr_sm.fit()
#pull the beta parameters out from results_sm
beta0_sm = results_sm.params[0]
beta1_sm = results_sm.params[1]
print("(beta0, beta1) = (%f, %f)" %(beta0_sm, beta1_sm))
Besides the beta parameters, results_sm contains a ton of other potentially useful information. Type results_sm and hit tab to see.
Below is the code for sklearn.
#build the least squares model
toyregr_skl = linear_model.LinearRegression()
#save regression info (parameters, etc) in results_skl
results_skl = toyregr_skl.fit(x_train,y_train)
#pull the beta parameters out from results_skl
beta0_skl = toyregr_skl.intercept_
beta1_skl = toyregr_skl.coef_[0]
print("(beta0, beta1) = (%f, %f)" %(beta0_skl, beta1_skl))
We should feel pretty good about ourselves now, and we're ready to move on to a real problem!
Part 2: Simple linear regression with automobile data [30 minutes]¶
We will now use sklearn to to predict automobile milesage per gallon (mpg) and evaluate these predictions. We first load the data and split them into a training set and a testing set.
#load mtcars
dfcars=pd.read_csv("../data/mtcars.csv")
dfcars=dfcars.rename(columns={"Unnamed: 0":"name"})
dfcars.head()
#split into training set and testing set
from sklearn.cross_validation import train_test_split
#set random_state to get the same split every time
traindf, testdf = train_test_split(dfcars, test_size=0.3, random_state=6)
#testing set is ~30% of the total data; training set is ~70%
dfcars.shape, traindf.shape, testdf.shape
We need to choose the variables that we think will be good predictors for the dependent variable mpg.
EXERCISE: Pick one variable to use as a predictor for simple linear regression. Create a markdown cell below and discuss your reasons. You may want to justify this with some visualizations. Is there a second variable you'd like to use as well, say for multiple linear regression with two predictors?
#your code (if any) here
EXERCISE: With either sklearn or statsmodels, fit the training data using simple linear regression. Use the model to make mpg predictions on testing set.
Plot the data and the prediction.
Print out the mean squared error for the training set and the testing set and compare.
#your code here
#define predictor and response for training set
# define predictor and response for testing set
#your code here
# create linear regression object with sklearn
#your code here
# train the model and make predictions
#your code here
#print out coefficients
# your code here
# Plot outputs
Part 3: Multiple linear regression with automobile data [15 minutes]¶
EXERCISE: With either sklearn or statsmodels, fit the training data using multiple linear regression with two predictors. Use the model to make mpg predictions on testing set. Print out the mean squared error for the training set and the testing set and compare.
How do these training and testing mean squared errors compare to those from the simple linear regression?
Time permitting, repeat the training and testing with three predictors and calculate the mean squared errors. How do these compare to the errors from the one and two predictor models?
#your code here
Part 4: Interpreting results [5 minutes / remaining time]¶
Tell a story with your results.