Programming Expectations¶
All assignments for this class will use Python and the browser-based iPython notebook format you are currently viewing. Python experience is not a prerequisite for this course, as long as you are comfortable learning on your own as needed. While we strive to make the programming component of this course straightforward, we won't devote much time to teaching programming or Python syntax.
Note though that the programming at the level of CS 50 is a prerequisite for this course. If you have concerns about the prerequisite, please come speak with any of the instructors.
We will refer to the Python 3 documentation in this lab and throughout the course. There are also many introductory tutorials to help build programming skills, which we are listed in the last section of this lab.
Table of Contents¶
- Learning Goals
- Getting Started
- Lists
- Strings and Listiness
- Dictionaries
- Functions
- Text Analysis of Hamlet
- References
Part 0: Learning Goals¶
This introductory lab is a condensed tutorial in Python programming. By the end of this lab, you will feel more comfortable:
Writing short Python code using functions, loops, arrays, dictionaries, strings, if statements.
Manipulating Python lists and recognizing the listy properties of other Python containers.
Learning and reading Python documentation.
Lab 0 relates to material in lecture 0,1,2,3 and homework 0.
Part 1: Getting Started¶
Importing modules¶
All notebooks should begin with code that imports modules, collections of built-in, commonly-used Python functions. Below we import the Numpy module, a fast numerical programming library for scientific computing. Future labs will require additional modules, which we'll import with the same import MODULE_NAME as MODULE_NICKNAME syntax.
import numpy as np #imports a fast numerical programming library
Now that Numpy has been imported, we can access some useful functions. For example, we can use mean to calculate the mean of a set of numbers.
np.mean([1.2, 2, 3.3])
to calculate the mean of 1.2, 2, and 3.3.
The code above is not particularly efficient, and efficiency will be important for you when dealing with large data sets. In Lab 1 we will see more efficient options.
Calculations and variables¶
At the most basic level we can use Python as a simple calculator.
1 + 2
Notice integer division (//) and floating-point error below!
1/2, 1//2, 1.0/2.0, 3*3.2
The last line in a cell is returned as the output value, as above. For cells with multiple lines of results, we can display results using print, as can be seen below.
print(1 + 3.0, "\n", 9, 7)
5/3
We can store integer or floating point values as variables. The other basic Python data types -- booleans, strings, lists -- can also be stored as variables.
a = 1
b = 2.0
Here is the storing of a list:
a = [1, 2, 3]
Think of a variable as a label for a value, not a box in which you put the value

(image taken from Fluent Python by Luciano Ramalho)
b = a
b
This DOES NOT create a new copy of a. It merely puts a new label on the memory at a, as can be seen by the following code:
print("a", a)
print("b", b)
a[1] = 7
print("a after change", a)
print("b after change", b)
Multiple items on one line in the interface are returned as a tuple, an immutable sequence of Python objects.
a = 1
b = 2.0
a + a, a - b, b * b, 10*a
We can obtain the type of a variable, and use boolean comparisons to test these types.
type(a) == float
type(a) == int
For reference, below are common arithmetic and comparison operations.
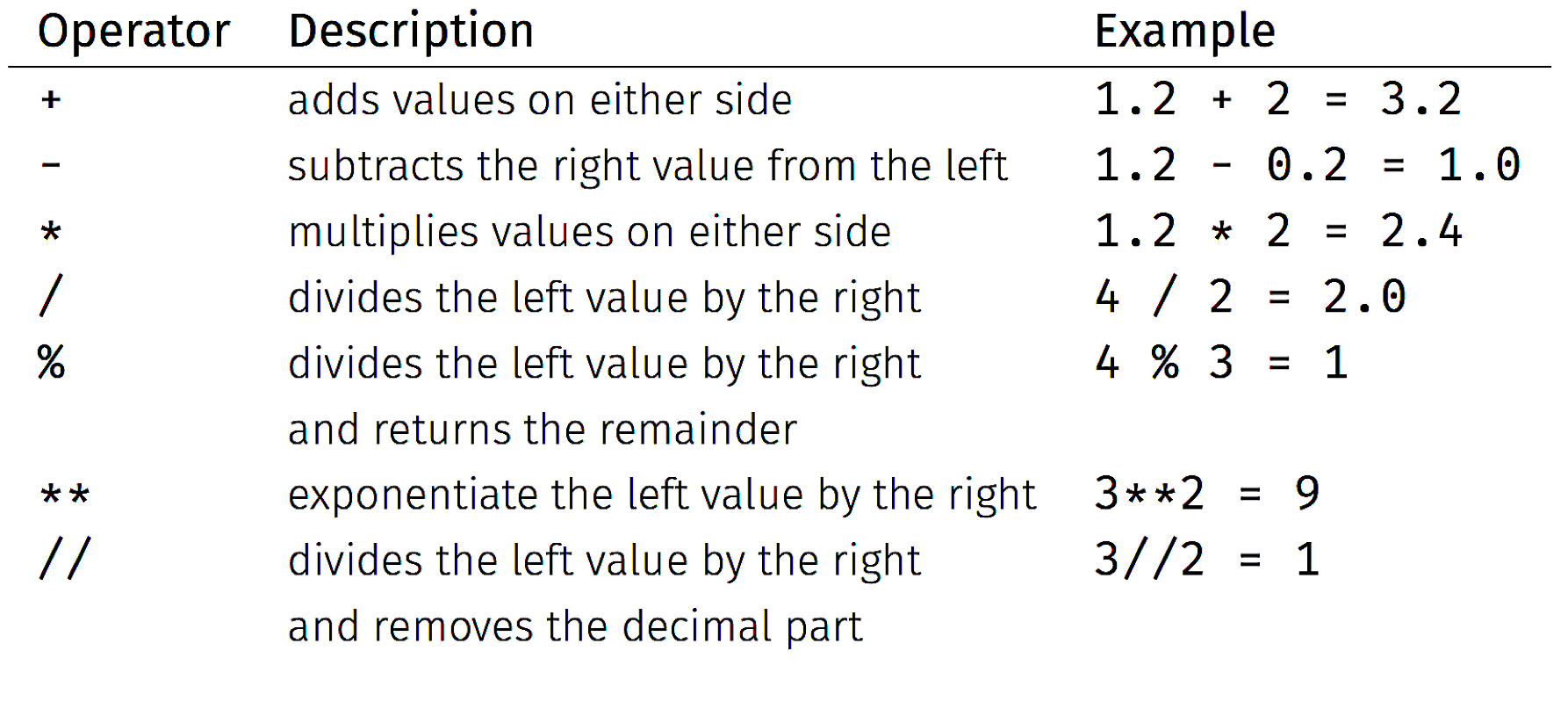

EXERCISE: Create a tuple called
tupwith the following seven objects:
- The first element is an integer of your choice
- The second element is a float of your choice
- The third element is the sum of the first two elements
- The fourth element is the difference of the first two elements
- The fifth element is first element divided by the second element
Display the output of
tup. What is the type of the variabletup? What happens if you try and chage an item in the tuple?
# your code here
Part 2: Lists¶
Much of Python is based on the notion of a list. In Python, a list is a sequence of items separated by commas, all within square brackets. The items can be integers, floating points, or another type. Unlike in C arrays, items in a Python list can be different types, so Python lists are more versatile than traditional arrays in C or in other languages.
Let's start out by creating a few lists.
empty_list = []
float_list = [1., 3., 5., 4., 2.]
int_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
mixed_list = [1, 2., 3, 4., 5]
print(empty_list)
print(int_list)
print(mixed_list, float_list)
Lists in Python are zero-indexed, as in C. The first entry of the list has index 0, the second has index 1, and so on.
print(int_list[0])
print(float_list[1])
What happens if we try to use an index that doesn't exist for that list? Python will complain!
print(float_list[10])
A list has a length at any given point in the execution of the code, which we can find using the len function.
print(float_list)
len(float_list)
Indexing on lists¶
And since Python is zero-indexed, the last element of float_list is
float_list[len(float_list)-1]
It is more idiomatic in python to use -1 for the last element, -2 for the second last, and so on
float_list[-1]
We can use the : operator to access a subset of the list. This is called slicing.
print(float_list[1:5])
print(float_list[0:2])
Below is a summary of list slicing operations:

You can slice "backwards" as well:
float_list[:-2] # up to second last
float_list[:4] # up to but not including 5th element
You can also slice with a stride:
float_list[:4:2] # above but skipping every second element
We can iterate through a list using a loop. Here's a for loop.
for ele in float_list:
print(ele)
Or, if we like, we can iterate through a list using the indices using a for loop with in range. This is not idiomatic and is not recommended, but accomplishes the same thing as above.
for i in range(len(float_list)):
print(float_list[i])
What if you wanted the index as well?
Python has other useful functions such as enumerate, which can be used to create a list of tuples with each tuple of the form (index, value).
for i, ele in enumerate(float_list):
print(i,ele)
list(enumerate(float_list))
This is an example of an iterator, something that can be used to set up an iteration. When you call enumerate, a list if tuples is not created. Rather an object is created, which when iterated over (or when the list function is called using it as an argument), acts like you are in a loop, outputting one tuple at a time.
Appending and deleting¶
We can also append items to the end of the list using the + operator or with append.
float_list + [.333]
float_list.append(.444)
print(float_list)
len(float_list)
Go and run the cell with float_list.append a second time. Then run the next line. What happens?
To remove an item from the list, use del.
del(float_list[2])
print(float_list)
List Comprehensions¶
Lists can be constructed in a compact way using a list comprehension. Here's a simple example.
squaredlist = [i*i for i in int_list]
squaredlist
And here's a more complicated one, requiring a conditional.
comp_list1 = [2*i for i in squaredlist if i % 2 == 0]
print(comp_list1)
This is entirely equivalent to creating comp_list1 using a loop with a conditional, as below:
comp_list2 = []
for i in squaredlist:
if i % 2 == 0:
comp_list2.append(2*i)
comp_list2
The list comprehension syntax
[expression for item in list if conditional]is equivalent to the syntax
for item in list:
if conditional:
expressionEXERCISE: Build a list that contains every prime number between 1 and 100, in two different ways:
- Using for loops and conditional if statements.
- (Stretch Goal) Using a list comprehension. You should be able to do this in one line of code, and it may be helpful to look up the function
allin the documentation.
# your code here
# your code here
Part 3: Strings and listiness¶
A list is a container that holds a bunch of objects. We're particularly interested in Python lists because many other containers in Python, like strings, dictionaries, numpy arrays, pandas series and dataframes, and iterators like enumerate, have list-like properties. This is known as duck typing, a term coined by Alex Martelli, which refers to the notion that if it quacks like a duck, it is a duck. We'll soon see that these containers quack like lists, so for practical purposes we can think of these containers as lists! They are listy!
Containers that are listy have a set length, can be sliced, and can be iterated over with a loop. Let's look at some listy containers now.
Strings¶
We claim that strings are listy. Here's a string.
astring = "kevin"
Like lists, this string has a set length, the number of characters in the string.
len(astring)
Like lists, we can slice the string.
print(astring[0:2])
print(astring[0:6:2])
print(astring[-1])
And we can iterate through the string with a loop. Below is a while loop:
i = 0
while i < len(astring):
print(astring[i])
i = i + 1
This is equivalent to the for loop:
for character in astring:
print(character)
So strings are listy.
How are strings different from lists? While lists are mutable, strings are immutable. Note that an error occurs when we try to change the second elemnt of string_list from 1 to b.
print(float_list)
float_list[1] = 2.09
print(float_list)
print(astring)
astring[1] = 'b'
print(astring)
We can't use append but we can concatenate with +. Why is this?
astring = astring + ', pavlos, ' + 'rahul, ' + 'margo'
print(astring)
type(astring)
What is happening here is that we are creating a new string in memory when we do astring + ', pavlos, ' + 'rahul, ' + 'margo'. Then we are relabelling this string with the old lavel astring. This means that the old memory that astring labelled is forgotten. What happens to it? We'll find out in lab 1.
Or we could use join. See below for a summary of common string operations.

To summarize this section, for practical purposes all containers that are listy have the following properties:
- Have a set length, which you can find using
len - Are iterable (via a loop)
- Are sliceable via : operations
We will encounter other listy containers soon.
EXERCISE: Make three strings, called
first,middle, andlast, with your first, middle, and last names, respectively. If you don't have a middle name, make up a middle name!Then create a string called
full_namethat joins your first, middle, and last name, with a space separating your first, middle, and last names.Finally make a string called
full_name_revwhich takesfull_nameand reverses the letters. For example, iffull_nameisJane Beth Doe, thenfull_name_reviseoD hteB enaJ.
list(range(-1, -5))
# your code here
Part 4: Dictionaries¶
A dictionary is another storage container. Like a list, a dictionary is a sequence of items. Unlike a list, a dictionary is unordered and its items are accessed with keys and not integer positions.
Dictionaries are the closest container we have to a database.
Let's make a dictionary with a few Harvard courses and their corresponding enrollment numbers.
enroll2016_dict = {'CS50': 692, 'CS109 / Stat 121 / AC 209': 312, 'Econ1011a': 95, 'AM21a': 153, 'Stat110': 485}
enroll2016_dict
enroll2016_dict.values()
enroll2016_dict.items()
for key, value in enroll2016_dict.items():
print("%s: %d" %(key, value))
Simply iterating over a dictionary gives us the keys. This is useful when we want to do something with each item:
second_dict={}
for key in enroll2016_dict:
second_dict[key] = enroll2016_dict[key]
second_dict
The above is an actual copy to another part of memory, unlike, second_dict = enroll2016_dict which would have made both variables label the same meory location.
In this example, the keys are strings corresponding to course names. Keys don't have to be strings though.
Like lists, you can construct dictionaries using a dictionary comprehension, which is similar to a list comprehension. Notice the brackets {} and the use of zip, which is another iterator that combines two lists together.
my_dict = {k:v for (k, v) in zip(int_list, float_list)}
my_dict
You can also create dictionaries nicely using the constructor function dict.
dict(a = 1, b = 2)
While dictionaries have some similarity to lists, they are not listy. They do have a set length, and the can be iterated through with a loop, but they cannot be sliced, since they have no sense of an order. In technical terms, they satisfy, along with lists and strings, Python's Sequence protocol, which is a higher abstraction than that of a list.
A cautionary word on iterators (read at home)¶
Iterators are a bit different from lists in the sense that they can be "exhausted". Perhaps its best to explain with an example
an_iterator = enumerate(astring)
type(an_iterator)
for i, c in an_iterator:
print(i,c)
for i, c in an_iterator:
print(i,c)
What happens, you get nothing when you run this again! This is because the iterator has been "exhausted", ie, all its items are used up. I have had answers go wrong for me because I wasnt careful about this. You must either track the state of the iterator or bypass this problem by not storing enumerate(BLA) in a variable, so that you dont inadvertantly "use that variable" twice.
Part 5: Functions¶
A function is a reusable block of code that does a specfic task. Functions are all over Python, either on their own or on objects.
We've seen built-in Python functions and methods. For example, len and print are built-in Python functions. And at the beginning of the lab, you called np.mean to calculate the mean of three numbers, where mean is a function in the numpy module and numpy was abbreviated as np. This syntax allow us to have multiple "mean" functions" in different modules; calling this one as np.mean guarantees that we will pick up numpy's mean function.
Methods¶
A function that belongs to an object is called a method. An example of this is append on an existing list. In other words, a method is a function on an instance of a type of object (also called class, here the list type).
print(float_list)
float_list.append(56.7)
float_list
User-defined functions¶
We'll now learn to write our own user-defined functions. Below is the syntax for defining a basic function with one input argument and one output. You can also define functions with no input or output arguments, or multiple input or output arguments.
def name_of_function(arg):
...
return(output)The simplest function has no arguments whatsoever.
def print_greeting():
print("Hello, welcome to CS 109 / Stat 121 / AC 209a / CSCI E-109A!")
print_greeting()
We can write functions with one input and one output argument. Here are two such functions.
def square(x):
x_sqr = x*x
return(x_sqr)
def cube(x):
x_cub = x*x*x
return(x_cub)
square(5),cube(5)
Lambda functions¶
Often we define a mathematical function with a quick one-line function called a lambda. No return statement is needed.
The big use of lambda functions in data science is for mathematical functions.
square = lambda x: x*x
print(square(3))
hypotenuse = lambda x, y: x*x + y*y
## Same as
# def hypotenuse(x, y):
# return(x*x + y*y)
hypotenuse(3,4)
Refactoring using functions¶
EXERCISE: Write a function called
isprimethat takes in a positive integer $N$, and determines whether or not it is prime. Return the $N$ if it's prime and return nothing if it isn't. You may want to reuse part of your code from the exercise in Part 2.Then, using a list comprehension and
isprime, create a listmyprimesthat contains all the prime numbers less than 100.
# your code here
Notice that what you just did is a refactoring of the algorithm you used earlier to find primes smaller than 100. This implementation reads much cleaner, and the function isprime which containes the "kernel" of the functionality of the algorithm can be re-used in other places. You should endeavor to write code like this.
Default Arguments¶
Functions may also have default argument values. Functions with default values are used extensively in many libraries.
# This function can be called with x and y, in which case it will return x*y;
# or it can be called with x only, in which case it will return x*1.
def get_multiple(x, y = 1):
return x*y
print("With x and y:", get_multiple(10, 2))
print("With x only:", get_multiple(10))
We can have multiple default values.
def print_special_greeting(name, leaving = False, condition = "nice"):
print("Hi", name)
print("How are you doing on this", condition, "day?")
if leaving:
print("Please come back! ")
# Use all the default arguments.
print_special_greeting("Rahul")
Or change all the default arguments:
print_special_greeting("Rahul", True, "rainy")
Or use the first default argument but change the second one.
print_special_greeting("Rahul", condition="horrible")
Positional and keyword arguments¶
These allow for even more flexibility.
Positional arguments are used when you don't know how many input arguments your function be given. Notice the single asterisk before the second argument name.
def print_siblings(name, *siblings):
print(name, "has the following siblings:")
for sibling in siblings:
print(sibling)
print()
print_siblings("John", "Ashley", "Lauren", "Arthur")
print_siblings("Mike", "John")
print_siblings("Terry")
In the function above, arguments after the first input will go into a list called siblings. We can then process that list to extract the names.
Keyword arguments mix the named argument and positional properties. Notice the double asterisks before the second argument name.
def print_brothers_sisters(name, **siblings):
print(name, "has the following siblings:")
for sibling in siblings:
print(sibling, ":", siblings[sibling])
print()
print_brothers_sisters("John", Ashley="sister", Lauren="sister", Arthur="brother")
Putting things together¶
Finally, when putting all those things together one must follow a certain order: Below is a more general function definition. The ordering of the inputs is key: arguments, default, positional, keyword arguments.
def name_of_function(arg1, arg2, opt1=True, opt2="CS109", *args, **kwargs):
...
return(output1, output2, ...)Positional arguments are stored in a tuple, and keyword arguments in a dictionary.
def f(a, b, c=5, *tupleargs, **dictargs):
print("got", a, b, c, tupleargs, dictargs)
return a
print(f(1,3))
print(f(1, 3, c=4, d=1, e=3))
print(f(1, 3, 9, 11, d=1, e=3)) # try calling with c = 9 to see what happens!
Functions are first class¶
Python functions are first class, meaning that we can pass functions to other functions, built-in or user-defined.
def sum_of_anything(x, y, f):
print(x, y, f)
return(f(x) + f(y))
sum_of_anything(3,4,square)
Finally, it's important to note that any name defined in this notebook is done at the global scope. This means if you define your own len function, you will overshadow the system len.
EXERCISE: Create a dictionary, called
ps_dict, that contains with the primes less than 100 and their corresponding squares.
# your code here
Part 6. Numpy¶
Scientific Python code uses a fast array structure, called the numpy array. Those who have worked in Matlab will find this very natural. Let's make a numpy array.
my_array = np.array([1, 2, 3, 4])
my_array
Numpy arrays are listy. Below we compute length, slice, and iterate. But these are very bad ideas, for efficiency reasons we will see in lab 1.
print(len(my_array))
print(my_array[2:4])
for ele in my_array:
print(ele)
In general you should manipulate numpy arrays by using numpy module functions (np.mean, for example). You can calculate the mean of the array elements either by calling the method .mean on a numpy array or by applying the function np.mean with the numpy array as an argument.
print(my_array.mean())
print(np.mean(my_array))
You can construct a normal distribution with mean0 and standard deviation 1 by doing:
normal_array = np.random.randn(1000)
print("The sample mean and standard devation are %f and %f, respectively." %(np.mean(normal_array), np.std(normal_array)))
Numpy supports a concept known as broadcasting, which dictates how arrays of different sizes are combined together. There are too many rules to list here, but importantly, multiplying an array by a number multiplies each element by the number. Adding a number adds the number to each element. This means that if you wanted the distribution $N(5, 7)$ you could do:
normal_5_7 = 5 + 7*normal_array
np.mean(normal_5_7), np.std(normal_5_7)
Part 7: Text Analysis of Hamlet (try it at home)¶
Below we'll walk you through an exercise analyzing the word distribution of the play Hamlet using what we learned in this lab.
First we need to read the file into Python. If you haven't done so already, please download hamlet.txt from the github repo and save it in the data subfolder. (You could just clone and download a zip of the entire repository as well).
EXERCISE: Read the documentation on reading and writing files. Open and read in and save
hamlet.txtashamlettext. Then close the file.
# your code here
EXERCISE: Before moving on, let's make sure
hamlettextactually contains the text of Hamlet. First, what is the type ofhamlettext? What is its length? Print the first 500 items ofhamlettext.
# your code here
Each item in hamlettext is a text character. Let's see what we can learn about the distribution of words in the play. To do this, you'll need to split the string hamlettext into a list of strings, where each element of the list is a word in the play. Search the documentation, or refer back to the summary of string operations in the Strings section of this lab.
EXERCISE: Create a list called
hamletwordswhere the items of thehamletwordsare the words of the play. Confirm thathamletwordsis a list, that each element ofhamletwordsis a string, and print the first 10 items inhamletwords. Print "There are $N$ total words in Hamlet," where $N$ is the total number of words in Hamlet.
# your code here
The total number of words above considers "The" and "the" as two different words. So if we're going to find the distribution of the words in the play, we need to first make all the words lower-case. From the lower-case list of words, we then find the set of unique words.
EXERCISE: Using a list comprehension, create a
hamletwords_lcwhich converts the items inhamletwordsto lower-case. You will likely want to search the documentation for the string methodlower. Then count the number of occurences of "thou", making use of the string methodcount.
# your code here
We need to find the unique set of words in hamletwords_lc.
EXERCISE: Use
setto determine the set of unique words inhamletwords_lc. Then print "There are $M$ unique words in Hamlet," where $M$ is the number of unique words. As a sanity check, verify that $M < N$.
# your code here
Next we want a dictionary with the number of occurrences of each unique word, with the unique words as dictionary keys.
EXERCISE: Create this dictionary. To do it you will use either a loop or a dictionary comprehension and the
countmethod.
# your code here
Finally, we find the 100 most frequently occurring words using the built-in sorted function.
EXERCISE: (Stretch Goal) Search and read the documentation for the
sortedfunction. The documentation has a link to some examples, "sorting HOW TO." Check out the example under the heading "Key Functions." Then create a list calledtop100wordswith the 100 most frequently occurring words in Hamlet.
# your code here
Now we'll plot the top distribution of the top 10 words on this list. To do this you'll need to import a plotting library called matplotlib. The pyplot module in this library contains a set of functions that are especially useful for generating a wide range of plots. Go back to the first cell in this notebook and type
````
import matplotlib
import matplotlib.pyplot as plt
````
In this cell, also type
````
%matplotlib inline
````
Be sure to evaluate the cell before continuing. Below is the code to generate the bar chart.
%matplotlib inline
import matplotlib.pyplot as plt
topfreq = top100words[:10]
pos = range(len(topfreq)) # get positions on graph
plt.bar(pos, [e[1] for e in topfreq]); # get second members of tuples, plot against positions
plt.xticks([e+0.4 for e in pos], [e[0] for e in topfreq]); # get labels as first members of tuples
plt.ylabel('Frequency')
This is a somewhat boring result because we forgot to remove common words like "the" from the corpus. That's a topic for a later date!
Part 8: References¶
Congratulations! You've completed lab 0. You'll likely very comfortable with some parts of the lab, and less comfortable with other parts. Below are a few tutorials and practice problems if you'd like to do more -- check them out.